Abstract
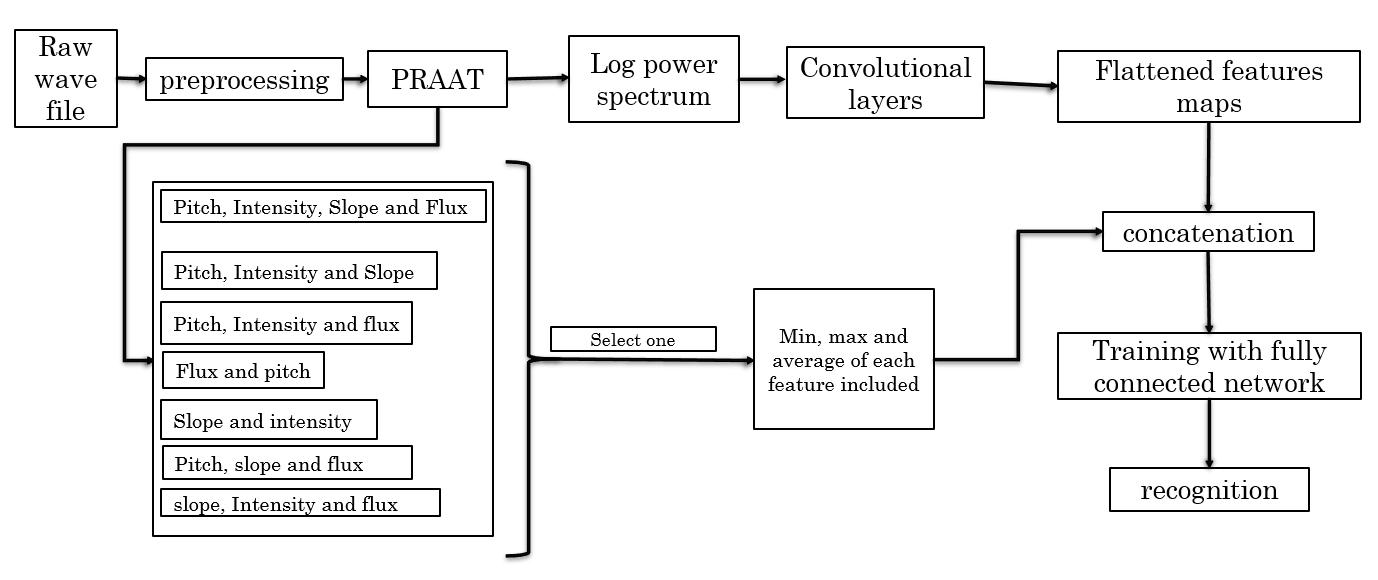
Speaker identification systems have gained significant attention due to their potential applications in security and personalized systems. This study evaluates the performance of various time and frequency domain physical features for text-independent speaker identification. Specifically, four key features—pitch, intensity, spectral flux, and spectral slope—were examined along with their statistical variations (minimum, maximum, and average values). These features were fused with log power spectral features and trained using a Convolutional Neural Network (CNN). The goal was to identify the most effective feature combinations for improving speaker identification accuracy. The experimental results revealed that the proposed feature fusion method outperformed the baseline system by 8%, achieving an accuracy of 87.18%.
Funding
This work was supported without any funding.
Cite This Article
APA Style
Shah, Z., Jang, G., & Farooq, A. (2024). Feature Fusion for Performance Enhancement of Text Independent Speaker Identification. IECE Transactions on Intelligent Systematics, 2(1), 27–37. https://doi.org/10.62762/TIS.2024.649374
Publisher's Note
IECE stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Institute of Emerging and Computer Engineers (IECE) or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.




 Submit Manuscript
Edit a Special Issue
Submit Manuscript
Edit a Special Issue