Abstract
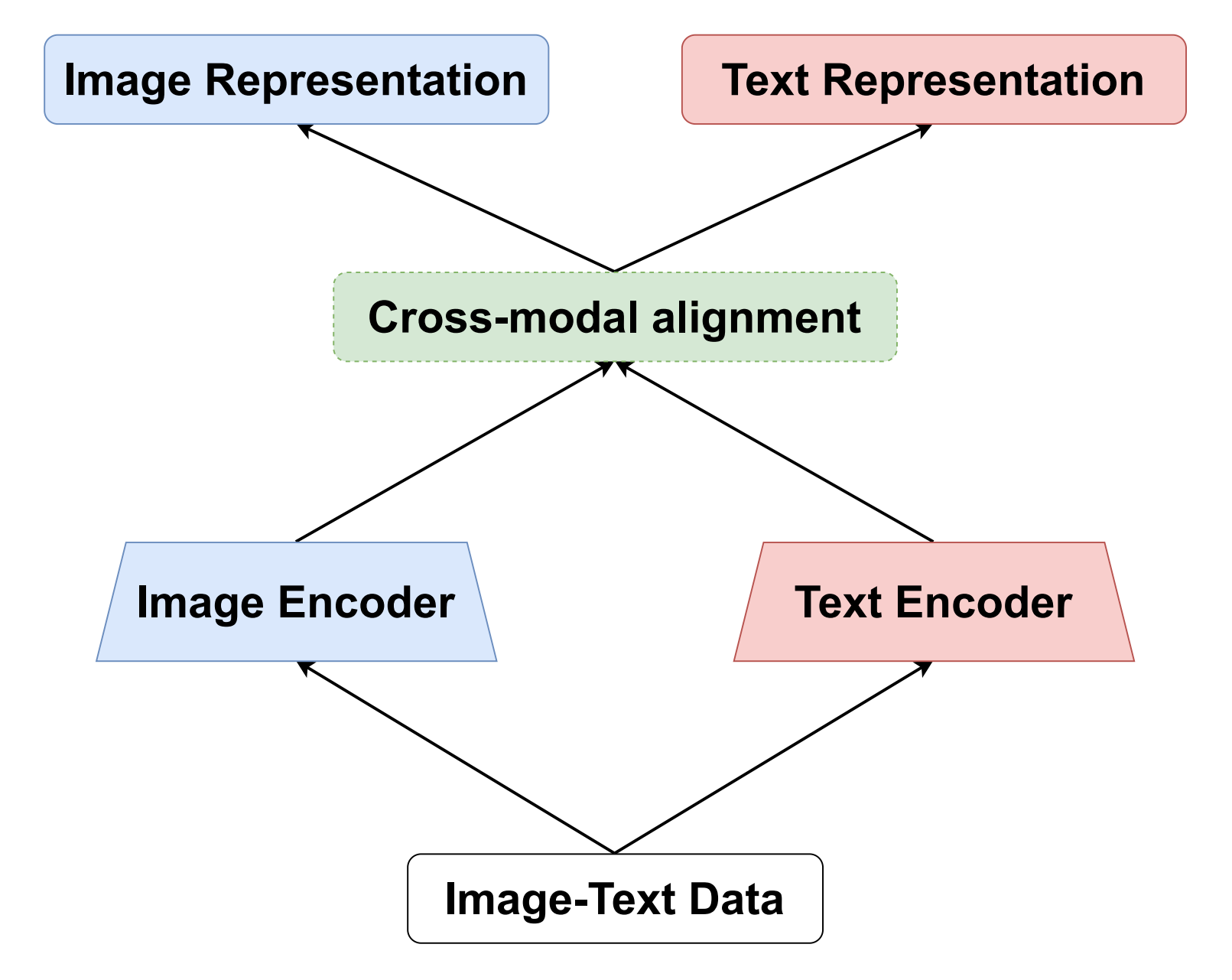
The rapid advancement of Internet technology, driven by social media and e-commerce platforms, has facilitated the generation and sharing of multimodal data, leading to increased interest in efficient cross-modal retrieval systems. Cross-modal image-text retrieval, encompassing tasks such as image query text (IqT) retrieval and text query image (TqI) retrieval, plays a crucial role in semantic searches across modalities. This paper presents a comprehensive survey of cross-modal image-text retrieval, addressing the limitations of previous studies that focused on single perspectives such as subspace learning or deep learning models. We categorize existing models into single-tower, dual-tower, real-value representation, and binary representation models based on their structure and feature representation. Additionally, we explore the impact of multimodal Large Language Models (MLLMs) on cross-modal retrieval. Our study also provides a detailed overview of common datasets, evaluation metrics, and performance comparisons of representative methods. Finally, we identify current challenges and propose future research directions to advance the field of cross-modal image-text retrieval.
Funding
The work is partially supported by the National Natural Science Foundation of China (Nos. U22A2025, 62072088, 62232007, U23A20309, 61991404), Liaoning Provincial Science and Technology Plan Project - Key R&D Department of Science and Technology (No.2023JH2/101300182), and 111 Project (No. B16009).
Cite This Article
APA Style
Li, T., Kong, L., Yang, X., Wang, B., & Xu, J. (2024). Bridging Modalities: A Survey of Cross-Modal Image-Text Retrieval. Chinese Journal of Information Fusion, 1(1), 79–92. https://doi.org/10.62762/CJIF.2024.361895
Publisher's Note
IECE stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Institute of Emerging and Computer Engineers (IECE) or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.






 Submit Manuscript
Edit a Special Issue
Submit Manuscript
Edit a Special Issue