
Journal of Artificial Intelligence in Bioinformatics
ISSN: request pending (Online) | ISSN: request pending (Print)
Email: [email protected]

Every day, a significant amount of video content is uploaded to social media platforms, including medical and health-related videos. These videos play a key role in educating patients, assisting in disease diagnosis, and supporting medical research. The rapid increase in video consumption, especially during the COVID-19 pandemic, highlights the growing role of video in online health consultations, virtual medical meetings, and educational conferences. For instance, YouTube saw its monthly video views grow from 4.67 billion to 11 billion due to the pandemic, with substantial contributions from online health-related content. This tremendous expansion of video content has had a significant impact on healthcare and bioinformatics, particularly in the extraction and analysis of emotions expressed in videos [1]. Emotion analysis in video content, especially in medical consultations or health-related discussions, can provide valuable insights for healthcare providers.
Due to the massive growth in video content on social media, the extraction of videos in keeping with emotions is a burdensome task for the user. In the past, online media sentiment research was mainly to calculate the sentimentality of online media. Emotion and sentiment analysis have become a new trend in social media, helping users and companies to automatically extract user-generated content, especially opinions expressed in videos and recommendation systems [2]. Emotions and sentiment are different from each other but sentiment relies on emotions while emotions are fleeting states of mind that come and go. Sentiments, on the other hand, last longer in our bodies and minds if we take the opportunity to learn about them [3]. Emotions occur unconsciously and will emerge and disappear quickly. When our mind intervenes and we recognize what we're doing, we call it a feeling. It takes time for sentiments to emerge from emotions. Emotions are more powerful as a result of this; sentiments necessitate the activation of more dynamic systems. While the Sentiment is often preceded by emotion. We can't have sentiments if we don't have impulses. In the same individual, the same emotion will elicit a variety of responses [4].
The basic method was to use natural language processing, text analysis, and computational linguistics to dig out people's opinions, sentiments, evaluations, attitudes, and attitudes from the text. The basic deployment is to build a system through some knowledge bases, plus some basic principles of statistics, to classify the text of the network, and to get its polarity and polarity strength which is not perfect for dealing with the emotions of video content for the user [5].
However, the traditional machine learning algorithms mostly use the bag-of-words model for the representation, they also face problems such as sparse data features and the inability to extract emotional information [6]. The deep learning methods that have emerged in recent years can well make up for the shortcomings of traditional machine learning methods. Deep learning models are represented by convolutional neural networks (CNN) and recurrent neural networks (RNN) while the objective of this work is to design a new framework that keeps the emotional information of video data for their viewers using the Bidirectional Encoder Representations model [7].
Different researchers performed sentiment analysis for the judgment of opinion using different well-known techniques to realize the reviews of their users about their content and product [8]. According to the method of sentiment classification, the application research of sentiment analysis in the field of online product reviews can be divided into two categories. The machine learning method is mainly to learn the emotional characteristics of the training set, estimate the dependency between the input and output of the system, and then apply it to the classification judgment of the test set [9]. But the emotions and sentiment in both terminologies are different from each other, sentiment relies on emotions, and the emotions are fleeting states of mind that come and go. Sentiments, on the other hand, last longer in our bodies and minds if we take the opportunity to learn about them [10]. Emotions occur unconsciously and will emerge and disappear quickly. When our mind intervenes and we recognize what we're doing, we call it a feeling. It takes time for sentiments to emerge from emotions. Emotions are more powerful as a result of this; sentiments necessitate the activation of more dynamic systems [11].
Social networks are developing into an ecological platform that "connects everything" and especially video content is increasing exponentially. Due to this massive growth in video content on social media, the extraction of videos in keeping with emotions is a burdensome task for the user. In the past, online media sentiment research was mainly to calculate the sentimentality of online media [12]. The basic method was to use natural language processing, text analysis, and computational linguistics to dig out people's opinions, sentiments, evaluations, attitudes, and attitudes from the text. The basic deployment is to build a system through some knowledge bases, plus some basic principles of statistics, to classify the text of the network, and to get its polarity and polarity strength which is not perfect for dealing with the emotions of video content for the user [11, 13].
Existing literature has found a large number of techniques that can be used for multiple tasks in sentiment analysis, including supervised and unsupervised methods. Among the supervised methods, early papers used all supervised machine learning methods (such as support vector machines, maximum entropy, naive Bayes, etc.) and feature combinations [14]. Unsupervised methods include different methods using sentiment dictionaries, grammatical analysis, and syntactic patterns. There are many review books and papers, covering the early methods and applications extensively. All of these studies are based on traditional big giants to realize the reviews of the users about their content [15]. But none of these classify the emotions of social media videos from the perspective of a user and make users more relaxed by the selection of video as per their mode interest [16, 17].
This section mainly focuses on the proposed framework to achieve the objective of the research. In this proposed framework, the social media video is considered as the primary research object, and different methods on it to classify the emotions of their users as shown in Figure 1.
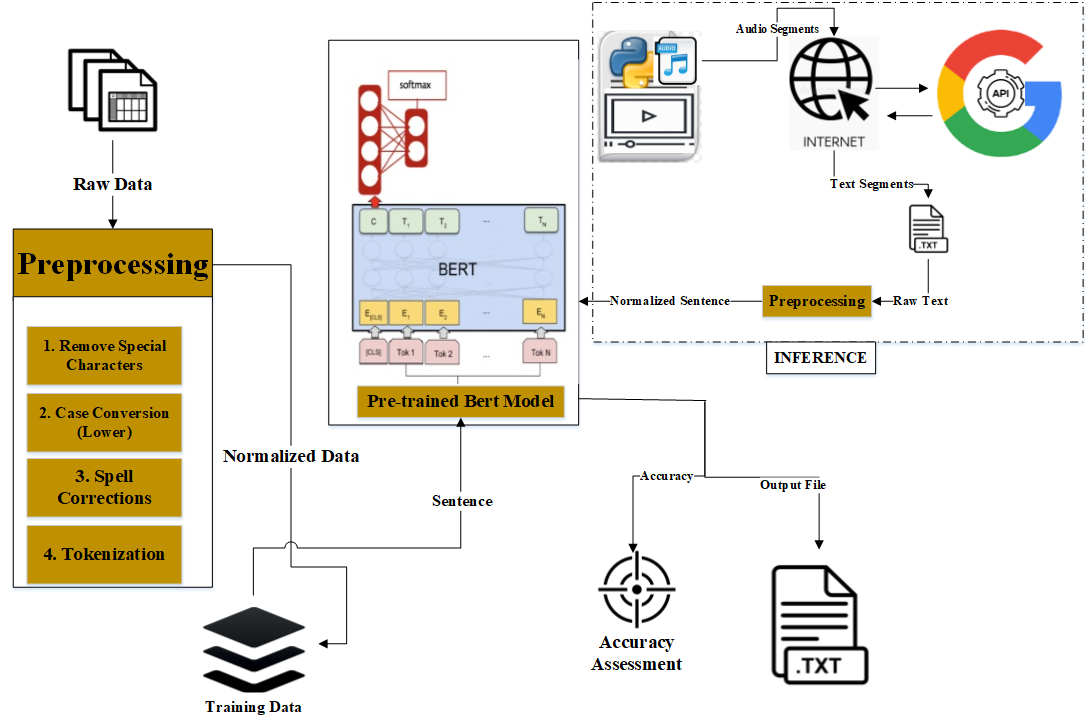
The proposed framework consists of two subsystems that are performed the evaluate the emotions of social media video data using bidirectional encoder representations.
In the training pipeline of a purposed framework, there are two following sub-steps.
First of all, the data needs to be preprocessed for the enhancement of the data quality to ultimately achieve the best results because it affects the overall performance of the system. In preprocessing, different methods as mentioned here.
Remove Special Character: The dataset contains grammatical words and other supporting words or POS to complete sentences that don't contain any core information about emotions. To increase the processing speed, remove the special characters from the dataset at the start of the procedure. With the help of Regular expression("regex"), the method removes all the special characters from the dataset and makes it more appropriate for further operations.
Case Conversion Operation: The conversion of the case utilizes the built function of python provided by the string library that converts all the upper case textual into the lower case to enhance the smoothness of the dataset.
Spell Correction: In spelling correction, correcting words of a textual dataset. There are many approaches but the adopted one is isolated words compute a list of spelling suggestions ranked by edit-distance, letter-n-gram similarity, or comparable measures.
Tokenization: Word Tokenization is the most commonly used tokenization algorithm. It splits a piece of text into individual words based on a certain delimiter. Depending upon delimiters, different word-level tokens are formed.
After the preprocessing operation, extracted the normalized data for the training of the model.
BERT (Bidirectional Encoder Representations from Transformers) has significantly advanced natural language processing (NLP) by introducing deep bidirectional contextual representations, enabling it to dynamically adapt to downstream tasks with task-specific modifications. Unlike earlier models such as ELMo, which rely on independently trained forward and backward LSTM cascades, BERT employs a more sophisticated bidirectional Transformer encoder, capturing dependencies in both directions simultaneously. This bidirectional learning mechanism enhances its ability to understand complex linguistic patterns, making it highly effective for tasks such as sentiment classification, emotion analysis, and text comprehension.
The pre-training phase of BERT utilizes two key objectives—Masked Language Modeling (MLM) and Next Sentence Prediction (NSP)—to develop rich contextual representations. MLM randomly masks input tokens, requiring the model to predict the missing words based on surrounding context, thereby improving its word-level semantic understanding. NSP, on the other hand, enhances sentence-level comprehension by training the model to determine whether two given sentences are contextually related. These techniques enable BERT to generate highly informative vector representations of words and sentences, ensuring optimal parameter initialization for subsequent fine-tuning tasks.
A critical component of BERT's superior performance lies in its input representation, which integrates token embeddings (capturing individual words or sub words), segment embeddings (differentiating between multiple sentences), and position embeddings (encoding sequential information). The summation of these embeddings creates a rich, high-dimensional representation, reinforcing the model's ability to effectively capture linguistic context across different tasks. Due to its extensive parameterization and fine-tuning capabilities, BERT consistently achieves state-of-the-art performance in various NLP applications, including emotion recognition from text.
To ensure optimal performance in fine-tuning BERT for emotion analysis, a comprehensive hyperparameter tuning process was conducted, leveraging structured search strategies. The AdamW optimizer with weight decay was employed to improve optimization stability, while a linear learning rate decay with warm-up was utilized to prevent overshooting in early training stages. Several training configurations were tested, with experiments spanning 3, 5, 10, and 15 epochs to assess convergence and overfitting trends, ultimately determining that 5 epochs provided the best balance between generalization and computational efficiency.
To refine the model further, Bayesian optimization was employed to efficiently explore the hyperparameter space, outperforming traditional grid search and random search methods by prioritizing high-performing configurations. Key hyperparameters were systematically varied, including batch size (8, 16, 32, 64), learning rate (1e-5, 2e-5, 3e-5, 5e-5), dropout rate (0.1, 0.2, 0.3, 0.4), and maximum sequence length (128, 256, 512). The optimal settings batch size of 32, learning rate of 3e-5, dropout rate of 0.1, and sequence length of 256 were selected to enhance training stability and generalization while preventing overfitting. Additionally, gradient clipping was applied to mitigate exploding gradients, ensuring robust learning dynamics.
By leveraging BERT's bidirectional Transformer encoder and systematically optimizing hyperparameters, this framework delivers a highly effective solution for emotion-based analysis of video content. The integration of contextualized embeddings, structured learning rate schedules, and Bayesian hyperparameter tuning enhances the model's ability to accurately capture emotional nuances within textual data. These advancements position the proposed approach as a state-of-the-art methodology for sentiment and emotion classification, demonstrating its efficacy in analyzing user responses to social media and video-based content [12].
Inference Engine is a core component that implements knowledge-based reasoning in an expert system. It is the realization of knowledge-based reasoning in a computer. It mainly includes two aspects of reasoning and control. It is an indispensable and important part of the knowledge system. The inference system compromises on the series of subsystems that incorporate to classify the emotions of the social media video from the viewer's perspective.
Video to Audio Conversion: First of all, a specified video is selected from a social media platform to convert into audio by using the nonlinear editing algorithm of Python. In this way, wav file is generated for the specified video.
Audio chunks to text Segments Conversion: Now the duration of the audio wave file is calculated and the whole duration of the audio is divided into 5 seconds. In this way, every 5-second audio chunk is converted into text using Google API.
Preprocessing approach: Polish the textual data by removing the unnecessary data from the extracted segments of text to enhance the data quality for the Fine Tune Bert model. In preprocessing, we performed different methods as earlier mentioned.
By doing immense research, we have extracted the intensities of emotions by the model and stored it in a separate file that describes the emotions of the social media video.
Furthermore, we applied a "maximum algorithm" to extract the most dominant emotions and mapped them to social media-selected videos for the perspectives of viewers and boosted their number because of their phraseology to make him/herself more relaxed.
To analyze the distribution of emotions in the dataset, we conducted an emotional word frequency analysis based on word reviews from all experimental text data. A tag cloud was generated, as shown in Figure 2, to visually represent the most frequently occurring emotional words. A tag cloud provides an intuitive depiction of text content by altering the font size and color of words based on their frequency, thereby highlighting the most prominent emotions expressed in the dataset. Words that appear more frequently in the dataset are displayed in larger and bolder fonts, while less frequent words appear smaller, allowing for quick identification of dominant emotional expressions. The tag cloud serves as an effective summary tool for analyzing the semantic structure of the dataset and understanding the prevalence of different emotions.

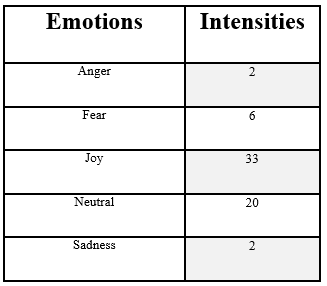
The chosen dataset deals with the five essential emotions; sadness, joy, neutrality, anger, and fear. Each sentence of training data holds one or many emotions as shown in Figure 3, which indicates the distribution of the training data is unbalanced. Emotions of sadness joy and neutrality appear more commonly as compared to anger and fear. Meanwhile, negative examples are fewer as compared to positive examples for each type of emotion.

We applied four different algorithms (Pre-trained Bert, CNN, LSTM, and SVM) to extract the emotions from the video for their viewers. To evaluate the predictive ability of the model that identifies the best model among them we used Model Performance Evaluation criteria and calculated the Accuracy, Error Rate, Precision Rate, Recall Rate, and F1 Measurement.
Accuracy refers to the proportion of the number of correctly classified samples to the total number of samples. It is a commonly used method to evaluate the generalization ability of a learning model as shown in Table 1. It can be measured by equation (1).
where and are the number of correctly classified samples. is the total number of samples. Both of these values can be extracted from the confusion matrix, which is the matrix, where is the number of predicted classes.
| Methods | Accuracy |
|---|---|
| CNN | 74% |
| LSTM | 73% |
| Pre Trained BERT | 83% |
| SVM | 72% |
Error rate refers to the proportion of misclassified samples to the total number of samples as shown in Table 2 for selective algorithms [18]. It can be calculated using equation (2).
where and are the total number of wrongly classified samples. is the total number of samples.
| Methods | Error Rate |
|---|---|
| CNN | 0.26 |
| LSTM | 0.27 |
| Pre-Trained BERT | 0.17 |
| SVM | 0.28 |
Precision Rate refers to the proportion of the true positive class among all the results predicted as the positive class as shown in Table 3. It can be defined as equation (3).
where is the total number of actual classified samples, and is the total number of the wrong sample that is mistakenly classified to be correct.
| Methods | Precision Rate |
|---|---|
| CNN | 0.75 |
| LSTM | 0.73 |
| Pre Trained BERT | 0.83 |
| SVM | 0.72 |
Recall rate refers to the proportion of the number of correctly classified samples by the model to the number of all positive samples. While Table 4 showed the recall rate of all selected algorithms and using equation (4) calculate the value of recall rate of an algorithm.
where are the number of correctly classified samples, and are the number of samples that are classified to be false.
| Methods | Recall Rate |
|---|---|
| CNN | 0.75 |
| LSTM | 0.73 |
| Pre Trained BERT | 0.83 |
| SVM | 0.73 |
F1-Measurement is the evaluation standard which is the harmonic average of the precision and recall and Table 5 shown the value of the F1 measure of selective algorithms. It can be measured by the given equation (5).
where and .
| Methods | F1 Score |
|---|---|
| CNN | 74 |
| LSTM | 73 |
| Pre-Trained BERT | 83 |
| SVM | 72 |
Evaluate the model's predictive ability on the test set according to the previously determined evaluation criteria and reveal that the Pre-Trained BERT model was found to be best as compared to all other models for this research work.
To explore the emotional, this research work takes sentence-level emotions as the research object which is taken from the SST (Speech to Text) operation of the extracted audio chunk of social media video. A sentence may contain a variety of emotions with different intensities and the Pre-trained BERT model is selected to dig out the intensity of emotion from the sentence-level text as shown in Figure 4.
Furthermore, we applied a "maximum algorithm" to extract the most dominant emotions and mapped them to social media-selected videos for the perspectives of viewers and boosted their number because of their phraseology to make him/herself more relaxed.
To further assess the effectiveness of the pre-trained BERT model in comparison to traditional deep learning and machine learning approaches for emotion analysis, a paired t-test was conducted to evaluate whether the observed performance differences were statistically significant. This test determines whether the mean accuracy differences across multiple experimental runs (N = 10) arise from random variation or represent a genuine improvement in classification performance. The statistical evaluation included comparisons between BERT, CNN, LSTM, and SVM, with accuracy scores recorded over 10 independent runs for each model. The null hypothesis () posited no significant difference in mean accuracy between BERT and the baseline models, while the alternative hypothesis () assumed that BERT outperforms the baselines. The results, presented in Table 6, indicate that BERT achieved significantly higher accuracy than CNN (+9%), LSTM (+10%), and SVM (+11%), with t-values of 5.12, 4.87, and 6.32, respectively. The p-values for all comparisons (p < 0.05) confirm the statistical significance of these differences, reinforcing that the superior performance of BERT is unlikely to be attributed to chance. These findings underscore the robust advantage of BERT's bidirectional Transformer-based architecture, which captures deep contextual dependencies more effectively than the sequential processing mechanisms in CNN and LSTM or the feature-based approach in SVM. The statistically validated improvements highlight BERT's potential in emotion-based video content analysis, demonstrating its superior ability to interpret emotional expressions in speech-derived text.
| Comparison | p-value |
|---|---|
| BERT vs. CNN | 0.0006 |
| BERT vs. LSTM | 0.0010 |
| BERT vs. SVM | 0.0003 |
| BERT vs LR | 0.000 |
The results of this study demonstrate that the pre-trained BERT model significantly outperforms traditional deep learning and machine learning approaches, achieving the highest accuracy, precision, recall, and F1 score across all evaluated models. One key aspect of model performance is the trade-off between precision and recall, particularly in the context of emotion analysis from speech-to-text data. While precision measures the proportion of correctly predicted positive instances among all predicted positives, recall evaluates the model's ability to correctly identify all relevant instances within the dataset. In highly imbalanced classification tasks, particularly in emotion recognition, an overemphasis on precision may lead to lower recall, meaning the model may fail to capture certain emotional expressions that do not appear frequently in the training data. Conversely, prioritizing recall may increase false positives, reducing the model's specificity in detecting nuanced emotions. Our results show that BERT maintains a strong balance between these metrics, minimizing the loss of relevant information while maintaining high classification accuracy.
Despite the strong performance of the proposed framework, this study has certain limitations. First, the model relies on pre-trained embeddings [19], which may not fully capture the domain-specific nuances of emotion in social media videos. Fine-tuning BERT on a larger, domain-specific dataset could further enhance its contextual understanding of emotion intensities. Second, the computational complexity of BERT poses challenges for real-time inference, particularly in resource-constrained environments. Optimizations such as quantization, pruning, or knowledge distillation could be explored to make the model more efficient while preserving its classification performance. Additionally, our approach does not incorporate multimodal features such as facial expressions, tone of voice, or visual cues, which play a crucial role in emotional perception. Future work should integrate multimodal learning techniques by combining audio, visual, and textual data to enhance the robustness of emotion classification.
Another potential direction for improvement is handling ambiguous emotions, where a sentence may express multiple overlapping emotions. Future research could explore hierarchical classification techniques or attention-based mechanisms to dynamically capture the intensity and variations of emotions within social media content [20]. Moreover, the application of large language models (LLMs) such as GPT-based architectures or hybrid transformer models could be investigated to further refine emotion recognition accuracy. Lastly, conducting a more comprehensive statistical significance analysis using additional benchmarks and expanding the dataset to include diverse linguistic and cultural variations could further validate the model's generalizability and effectiveness in real-world applications.
With the rapid popularization of the Internet and the rapid development of multimedia processing technology, video data from different fields is increasing at an alarming rate. This tremendous expansion has greatly changed the world while the COVID-19 pandemic also contributes appreciably because of online classes, meetings, and conference recordings. Solving the challenges faced by this tremendous expansion of video with emotions is a burdensome task for the user. This research work proposed an interactive framework based on the Pre-Trained BERT model to classify the emotions of video. The pre-trained BERT model is selected because of its higher results achieved by model evaluation criteria and performs well in the task of predicting emotions in comparison with other models. The Pre-Trained Model generates the output file that holds the information of emotions and applies a "maximum algorithm" on it to extract the most dominant emotions and maps it to social media selected videos for perspectives of viewers and boosts their number because of their phraseology to make him/herself more relaxed, which can significantly improve patient-provider communication and decision-making in clinical settings. Future research work can start from the text representation method to further improve the model's cross-domain ability to predict emotional intensity.
 Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Journal of Artificial Intelligence in Bioinformatics
ISSN: request pending (Online) | ISSN: request pending (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/