by
,

IECE Transactions on Sensing, Communication, and Control | Volume 1, Issue 1: 60-71, 2024 | DOI: 10.62762/TSCC.2024.212751
Abstract
The efficient extraction and fusion of video features to accurately identify complex and similar actions has consistently remained a significant research endeavor in the field of video action recognition. While adept at feature extraction, prevailing methodologies for video action recognition frequently exhibit suboptimal performance in the context of complex scenes and similar actions. This shortcoming arises primarily from their reliance on uni-dimensional feature extraction, thereby overlooking the interrelations among features and the significance of multi-dimensional fusion. To address this issue, this paper introduces an innovative framework predicated upon a soft correlation strategy... More >
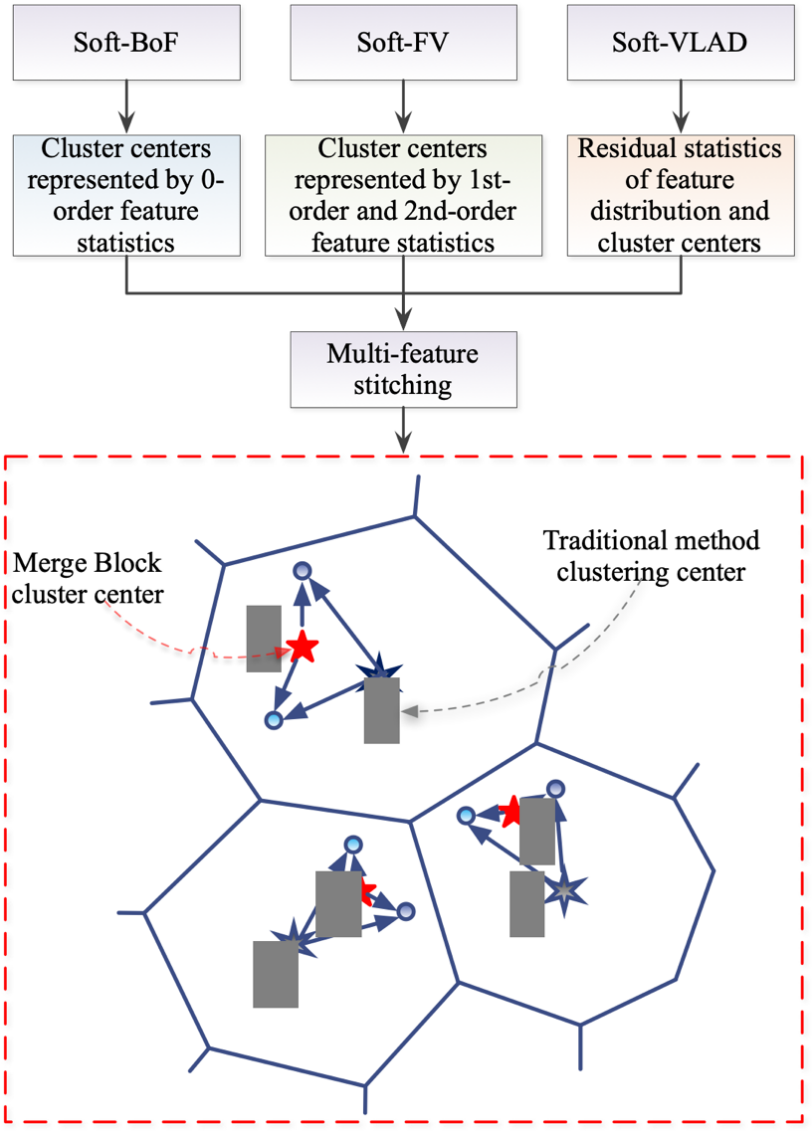
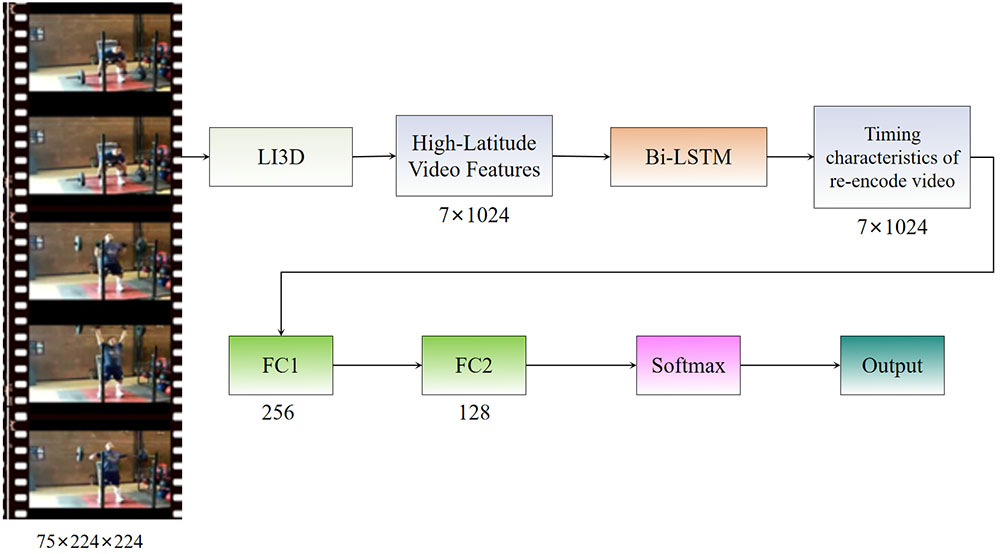
Graphical Abstract