


Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

In recent years, we have witnessed the success of deep learning in the field of image recognition, but such a breakthrough depends on a large amount of labeled data costing significant human labor. In contrast, humans are capable to master a certain knowledge with a few samples. Few-shot learning aims to mimic such an ability to extract class information by only viewing limited samples, which helps to solve the problem of large data requirements.
Meta-learning [1, 2] is one of the most popular methods for few-shot learning. It aims to learn a model that can extract prototypes for novel classes from a few data, based on which the test data are able to be distinguished by their feature similarities. Vinyals et al. [3] introduces two structures for support and query set to diversely extract the feature and compare the compound score for classification. ProtoNet methods [4, 5] use light structures to extract features and propose to measure the distance between prototypes and features in a shared metric space. Meta-Baseline [6] takes advantage of the base training and episodic training by combining them into two stages. In a word, These methods provide several simple and effective baselines with relatively less computational cost. Despite performing well, the proto-based method lacks the ability to extract high-quality prototypes only from visual domain, especially when the support sample is not representative. It is vital to enrich class information from other aspects.
To enhance the feature representation, semantic information is introduced during feature extraction [7, 8]. Xing et al. [9] adaptively combines the visual and semantic features with a learnable factor. KTN [12] aligns the fully connected node for base classes from both modals, and obtains new knowledge from the semantic modal for novel classes. Chen et al. [11] matches the deepest visual features with the word embedding and then uses the former to augment the feature with the nearest neighbor distance. CVAE [10] proposes a generative-adversarial structure to generate better auxiliary features. These methods introduce semantic information into FSL, but with simple mapping between visual and semantic features, without digging further messages. Such mapping may be helpful to some extent, but may not generate an ideal embedding space, leading to the limitation of generalization. Attribute methods [13, 14] go further into semantic information, they use component information of a class to divide visual features into several segments, each aligning with attribute embeddings. But they need extra attribute information labels in datasets for guidance, making the training cost higher. Compared with these methods, our proposed method takes class relations into consideration, which is easy to obtain by using word embedding.
In our opinion, it is more appropriate to learn the relationship among classes, rather than only direct features, since the semantic structure contains the core embedding information. For such purpose, we propose a novel FSL method that establishes a class-relation graph to guide the feature extraction, hoping the network can learn second-order relation messages. Specifically, we design an absolute constraint for direct feature mapping and a relation constraint for graph mapping among second-order relations. Furthermore, to improve feature representation with limited seen samples, we propose a Generative module and a Relation module to produce pseudo prototypes for modifying the support features in few-shot case. The former bridges word embedding and learned features to directly generate pseudo features for novel classes, while the other uses the word correlation between base and novel classes to incorporate the base prototypes for generation. The performance of our model shows state-of-the-art behavior in miniImageNet and CIFAR-FS, and achieving an improvement of 1.12%–3.8% in FC-100 for 1-shot case compared with the second-best method. It also has a first-class performance for 5-shot case. Our main contribution can be summarized as follows:
Using word embedding, we propose an absolute constraint a relation constraint to produce visual features with semantic information.
We propose a Generative Module and a Relation Module to produce pseudo features that can refine prototypes to class centers.
Our experiments show that our methods achieve state-of-the-art performance on three challenging datasets, miniImageNet, CIFAR-FS and FC-100.
Following the typical few-shot learning setting, a dataset contains a base set consisting of base classes , and a novel set with novel classes , in which . Firstly the goal is to train a feature extractor on base classes. Based on that, a set of few-shot classification tasks are constructed for novel class recognition. For a -way -shot task, classes are randomly chosen from , and a fixed quantity of samples are equally chosen among each class. After that, the support set is constructed by choosing labeled samples for each class, while the rest of the samples are used to construct query set , the aim of few-shot learning is to use information from to guide the classification of .
As the setting in [15], we use a two-branch structure to train the feature extractor: Apart from keeping the standard classification architecture, another branch with a new logistic regression structure is added after the penultimate layer, which retrieves possible rotation of each sample. And manifold-mixup [18] method is included for augmentation to improve the model robustness.
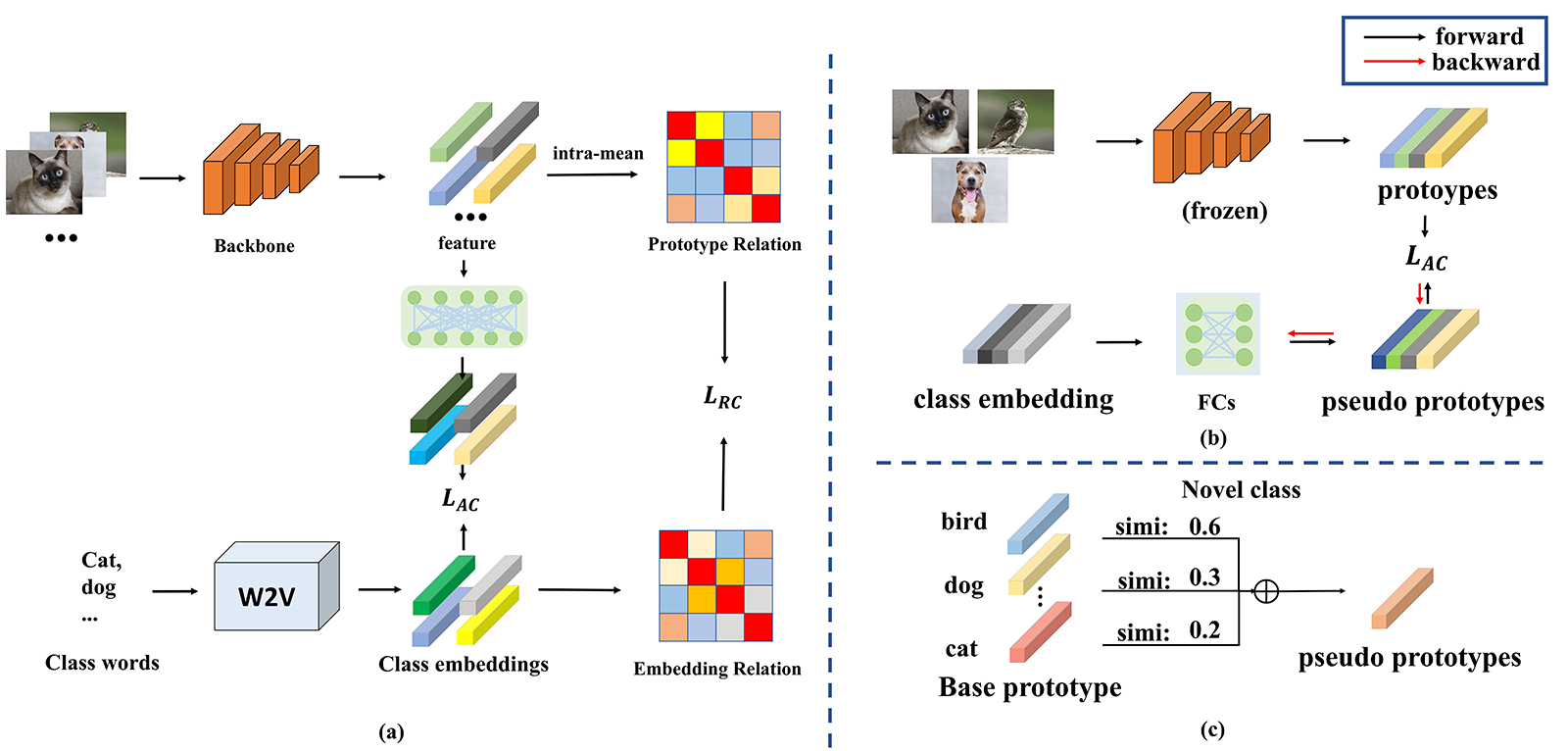
While the design above has good performance in regular classification, the embedding space it constructs lacks semantic relations among classes. For example, the class 'chair' and class 'desk' may have high semantic similarity in real world, but such relation may differ in the embedding space. To solve the problem, we introduce using word embedding information to guide the training. The architecture is shown as Figure 1(a), in which the main structure consists of: 1) Absolute Constraint, which forces features to match the corresponding word embedding. 2) Relation Constraint, which forces relations between class prototypes to match the similarity between semantic meanings by building a relation graph.
In this section, we hope that the extract features can directly learn the class representation ability of word embeddings, thus projecting features into word embeddings dimension with a simple 2-layer FC structure. Then we design a loss function. In details, given the features extracted from the backbone in a training batch, we assign word embeddings of base classes loaded from a Natural Language Processing model to form a direct restriction, to imitate its distribution. The word embedding label of each feature is chosen according to its class label: , where is the label of the -th sample and is the word embedding of all base classes. An embedding layer is then applied to match the channel dimension. The process can be represented as the following constraint:
where stands for a fully-connected layer and is the batch size. is the -th visual feature in a batch. stands for the projected features by fully-connected steucture
Although features extracted by backbone can represent class to some extent, the feature distribution, such as class relations, may not have the same structure as in real word. In this case, we need to use a good second-order structure to guide training, supposing that the extracted features not only have good ability of class representation. To achieve this, we use a class relation graph in each batch to guide the similarity of class prototypes. To use the relations among semantic information, we first calculate the prototypes of batch classes according to the labels:
where is the number of samples that belongs to class , equals to 1 if the inner condition is true. Then we establish the similarity relations between class semantics by using cosine similarity, and so done as for prototypes to calculate visual embedding relations:
where , are class index, and are corresponding prototypes and word embeddings. After that we use the following loss to keep the word relations among extracted visual prototypes:
Considering the classification loss, the overall objective for training the base model is as follows:
where and are hyperparamters to, and stands for the cross-entropy loss for regular classification restriction.
In order to further utilize the knowledge in semantic information for classes that is helpful to modify the support feature with a few samples, we extracted features from all trained samples after the base training, and calculate their class prototypes similarly as in Eq(2). We then apply them together with their word embeddings to generate pseudo prototypes for novel classes. Here we introduce two ways to achieve it: 1) A Generative Module that trains a structure that uses novel class embeddings to generate its visual features. 2) A Relation-based module that compounds similar base class prototypes according to the semantic relations between novel and base classes. By fusing the pseudo and the origin prototypes, the representation in few-shot case can be improved.
Generative Module(GM). One way to generate features is directly training a structure that is able to derive visual features according to their word embeddings. We use the base class word embedding as input for an FC layer, its output is set to approximate the corresponding prototypes. The process is illustrated in Figure 1(b). Once the training is finished, we use this structure to extract novel class pseudo prototypes according to the novel word embeddings.
Relation Module(RM). Another training-free approach is to aggregate the base prototypes according to the novel and base class relations. First, we construct the correlation matrix as done in (4) to find class correlations in semantic space, then we choose the base classes that have top-K similarities with a certain novel class to synthesize a pseudo prototype, as shown in Figure 1(c):
where is the index of novel classes and is the corresponding selected most similar base classes. stands for the prototype of the base class , represents the synthesized prototypes, and is the semantic similarity between novel class and base class , which is also computed with cosine similarity as in Eq(4). In order to compute the aggregation factor , we first compute similarities between novel class and all base classes, then choose the top-K similarity scores with the novel class for normalization to computed to compound factors.
During the testing stage, after we extract features both for support and query samples, we treat the novel class as input, either using GM or RM, to generate pseudo novel prototypes, which we incorporate with the support features for modifying the final class centers, where we directly calculate the mean of the two prototypes.
Dataset. We adopt three standard benchmark datasets that are widely used in few-shot learning: miniImageNet [3], a small subset extracted from ImageNet [19], consists of 100 classes with 600 images for each class. Following the setting, We split the data set into 64 classes for training, 16 classes for validation, and 20 classes for testing. CIFAR-FS [21], a subset randomly sampled from CIFAR-100 [22], is composed of 100 classes and 600 images for each class. It follows the same settings of split as miniImagNet and all samples have the same resolution of 3232. FC-100 [23], another subset chosen from CIFAR-100 with the same data size as CIFAR-FS, but has a different way of splitting settings. Rather than being divided according to classes, It is partitioned into 20 superclasses in total, with 12 for training, 4 for validation, and the rest 4 for testing.
Word-Embedding. Word2Vec [20] is a word embedding model to generate word vectors. It is trained with billions of online articles and sentences to extract word relations and creates an embedding for each word, so the embeddings for semantically-close words keep a similar correlation in the higher dimension. Here we use the pre-trained model offered by Google to directly generate embeddings for classes for simplicity.
Implementation Details. We set both and to 0.5. For fair comparisons, we use ResNet12 as backbone and adopt SGD for optimizer with a weight decay of 5e-4 and momentum of 0.9. The learning rate is initialized to 0.1 and adapted with a cosine learning rate scheduler. During the training, we also implement the strategy of S2M2R [18] to build a two-branch model for self-supervision, as done in baseline [15]. To testify our design, we follow the 5way-1shot and 5way-5shot paradigms to randomly generate 2000 episodes from test sets with 15 query samples for each class and report the mean accuracy with 95% confidence interval.
| |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Backbone | miniImageNet | cifar-fs | ||||||
| 1-shot | 5-shot | 1-shot | 5-shot | ||||||
| Matching Net [3] | ResNet-12 | 65.64 0.20 | 78.72 0.15 | - | - | ||||
| MAML [16] | ResNet-18 | 64.06 0.18 | 80.58 0.12 | - | - | ||||
| SimpleShot [17] | ResNet-18 | 62.85 0.20 | 80.02 0.14 | - | - | ||||
| S2M2R [18] | ResNet-18 | 64.93 0.18 | 83.18 0.11 | 63.66 0.17 | 76.07 0.19 | ||||
| DeepEMD [24] | ResNet-12 | 65.91 0.82 | 82.41 0.56 | 74.58 0.29 | 86.92 0.41 | ||||
| DSN [25] | ResNet-12 | 62.64 0.66 | 78.83 0.45 | 72.30 0.80 | 85.10 0.60 | ||||
| MetaOptNet [26] | ResNet-12 | 62.64 0.61 | 78.63 0.46 | 72.80 0.70 | 85.00 0.50 | ||||
| RFS [27] | ResNet-12 | 62.02 0.63 | 79.64 0.44 | 71.50 0.80 | 86.00 0.50 | ||||
| Inv-equ [28] | ResNet-12 | 67.28 0.80 | 84.78 0.50 | 77.87 0.85 | 89.74 0.57 | ||||
| R2-D2 [29] | ResNet-12 | 64.79 0.45 | 81.08 0.32 | 76.51 0.47 | 87.63 0.34 | ||||
| EASY [15] | ResNet-12 | 70.63 0.20 | 86.28 0.12 | 75.24 0.20 | 88.38 0.14 | ||||
| EASY 3 [15] | ResNet-12 | 71.75 0.19 | 87.15 0.12 | 76.20 0.20 | 89.00 0.14 | ||||
| FewTRUE [30] | ResNet-12 | 72.40 0.78 | 86.38 0.49 | 77.76 0.81 | 88.90 0.59 | ||||
| HCTransformer [31] | ResNet-12 | 74.74 0.17 | 85.66 0.10 | 78.89 0.18 | 87.73 0.11 | ||||
| Ours-baseline | ResNet-12 | 70.56 0.20 | 86.23 0.12 | 76.36 0.20 | 88.98 0.14 | ||||
| Ours-RM | ResNet-12 | 72.41 0.19 | 86.45 0.12 | 79.19 0.21 | 89.48 0.14 | ||||
| Ours-GM | ResNet-12 | 76.46 0.18 | 86.71 0.12 | 82.69 0.18 | 89.56 0.14 | ||||
| ||||||
|---|---|---|---|---|---|---|
| Method | Backbone | FC-100 | ||||
| 1-shot | 5-shot | |||||
| DeepEMD [24] | ResNet-12 | 46.60 0.26 | 63.22 0.71 | |||
| TADAM [23] | - | 40.10 0.40 | 56.10 0.40 | |||
| MetaOptNet [26] | ResNet-12 | 47.20 0.60 | 62.50 0.60 | |||
| RFS [27] | ResNet-12 | 42.60 0.70 | 59.10 0.60 | |||
| Inv-equ [28] | ResNet-12 | 47.76 0.77 | 65.30 0.76 | |||
| R2-D2 [29] | ResNet-12 | 44.75 0.43 | 59.94 0.41 | |||
| EASY [15] | ResNet-12 | 47.94 0.19 | 64.14 0.19 | |||
| FewTRUE [30] | - | 47.68 0.78 | 63.81 0.75 | |||
| Ours-baseline | ResNet-12 | 47.06 0.19 | 63.63 0.19 | |||
| Ours-RM | ResNet-12 | 47.98 0.20 | 63.88 0.19 | |||
| Ours-GM | ResNet-12 | 49.06 0.19 | 64.03 0.19 | |||
Table 1 compares the results on 5-way 1-shot and 5-way 5-shot benchmarks of our methods on miniImageNet and cifar-fs with other state-of-the-art few-shot learning methods. Our baseline model shows a close level with [15] since we keep its basic training structure. After including pseudo generation, we obtain 1.85 2.83 improvements on 1-shot task by using RM, and 5.9 6.33 improvements on 1-shot task by using GM. For the miniImageNet dataset, our methods achieve the best performance on 1-shot task, outperforming the current best one by 1.72, and the second best performance on 5-shot task. For cifar-fs dataset, our methods achieve the best by using GM and the second best by using RM on both tasks. Table 2 compares our method with the others on FC-100. It shows that both GM and RM pseudo generation can realize certain improvements on the baseline model, and still achieve first class by surpassing [15] by 1.3 on 1-shot task, but lags behind the best model on 5-shot task.
In total, compared with the well-behaved methods [15, 30, 31], our proposed method is more competitive with convincing results, which indicates that it can produce more representative features by matching features and word embeddings, along with pseudo generation to show it effectiveness. Such an advantage is more obvious as the number of support data decreases.
Influence of Modules. Our method can be divided into the use of proposed constraints and ways of pseudo generation. To explore their influence on the final outcome, we further conduct experiments with or without these designs. Table 3 illustrates that Relation constraint is more effective than Abosulte constraint, which indicates that rather than directly aligning the features to corresponding word embeddings, constructing the relations as in word embedding space is more helpful. But using both constraints can achieve further improvement. On the other hand, pseudo samples produced by GM outperform those by RM, which can infer that the class relation between base and novel classes in word embedding may differ in that in visual space, although we have matched those relations among base classes. This conclusion can also be testified when using two structures at the same time, the performance degrades compared using GM only. We infer that this is because the base class features we use to generate pseudo samples cannot cover the whole information of novel class, and it is unnecessary to take all base classes into consideration since it may not be helpful. In total, base on current dataset information, directly generating with FC layers can achieve a better outcome.
| Baseline | RM | GM | 1-shot | ||||
| ✓ | 70.56 0.20 | ||||||
| ✓ | ✓ | ✓ | 71.87 0.19 | ||||
| ✓ | ✓ | ✓ | 74.86 0.18 | ||||
| ✓ | ✓ | ✓ | 72.03 0.19 | ||||
| ✓ | ✓ | ✓ | 76.16 0.18 | ||||
| ✓ | ✓ | ✓ | ✓ | 72.41 0.19 | |||
| ✓ | ✓ | ✓ | ✓ | 76.46 0.18 | |||
| ✓ | ✓ | ✓ | ✓ | ✓ | 75.76 0.18 | ||
| |||||||
| 1-shot | ||||
| 0.5 | 0.3 | 76.17 0.20 | ||
| 0.5 | 0.4 | 76.37 0.19 | ||
| 0.5 | 0.5 | 76.90 0.18 | ||
| 0.5 | 0.6 | 76.36 0.19 | ||
| 0.5 | 0.7 | 76.25 0.18 | ||
| 0.3 | 0.5 | 76.62 0.19 | ||
| 0.4 | 0.5 | 76.72 0.18 | ||
| 0.5 | 0.5 | 76.90 0.18 | ||
| 0.6 | 0.5 | 76.63 0.19 | ||
| 0.7 | 0.5 | 76.54 0.18 | ||
| ||||
Influence of hyperparameters. To explore the influence of hyperparameters on loss functions. we conduct experiment on and separately by freezing one on 0.5 while testing the other. The comparison in Table 4 shows that the performance reaches the best when two hyperparameters are both set to 0.5. In detail, the accuracy in 1-shot case varies more rapidly when changing than , which implies that the model is more sensitive to the learning of relation graph than direct feature representation.
To test the computation complexity, we conduct the experiment on baseline model and our designed model on GFLOPS and amount of parameters. The outcome is shown in Table 5, it shows that compared to baseline model, the majority of extra computation cost lies on additional mapping structure while using GM, which is not significant. For using RM, the extra computation cost is by calculating similarities between novel class and base class matrix, which is far below the record scale. In total, our extra designed structures do not consume much resources.
| Method | GFLOPs | Param. |
|---|---|---|
| baseline | 3.52304 | 12.66M |
| Our-RM | 3.52324 | 12.66M |
| Our-GM | 4.12425 | 13.26M |
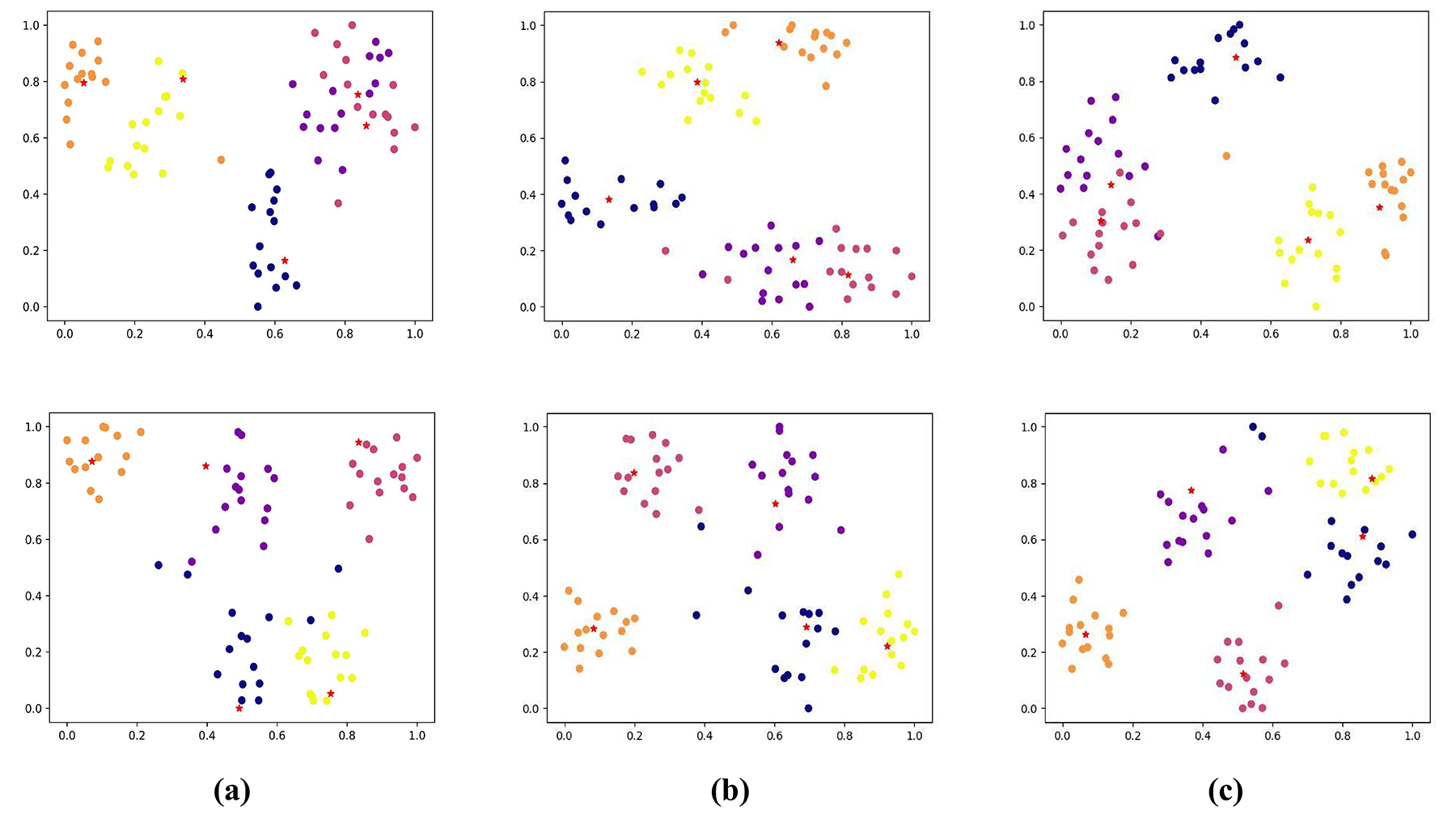
To make a direct demonstration, we conduct t-SNE plots in inference stage for clear comparison. The visualization of two test episodes are shown in Figure 2. In comparison, the class centers in our method using RM/GM modules are refined to the ideal positions, which are closer to the real centers of clusters, proving the effection of our method.
Although our method achieves good performance in few-shot datasets, there stills exists limitations. At first, our design is not an end-to-end structure, which needs extra training in GM case or novel class relations calculations in RM case. But designing end-to-end ones like GAN may be unstable because the volume of few-shot datasets is small. Secondly, the model lacks information when novel superclasses appears in inference stage, the trained relation graph is not well useful. In further study, these problems can be solved by using Large language models or supporting the model with larger datasets.
This paper proposes a few-shot learning method that utilizes word embeddings to solve the lack of data, which is a better fit for the real-world classification case. We introduce Absolute Constraint() for direct feature assignment and Relation Constraint() for class relation transfer to visual domain, which establishes a semantic-related structure for good reasoning. For clear advantage, we design Generative Module(GM) and Relation Module(RM) to construct pseudo support samples for the novel set to guide the recognition. Extensive experiments on multiple datasets and ablation study have proved our baseline model has achieved large improvement compared with baseline model. It provides an inspiration that good feature relation is helpful for few-shot learning.
 Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/