



Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Infrared sensors detect hidden target characteristics through thermal radiation and work under various weather and lighting conditions. The acquired images are often exhibit low contrast and lack fine details. On the contrary, visible sensors offer high-resolution scene perception through light reflection imaging. However, under adverse weather or camouflage conditions, visible sensors are difficult to distinguish obvious targets from the background environment. The image fusion technology can integrate the complementary information from different sensors into a single image, which can achieve superior visual description and scene understanding. A common application of fused images is to provide faster and more accurate visual interpretation for both human observers and computer systems. In addition, this technology has been extended into other visual tasks, such as person re-identification [1], object detection [2], and RGBT tracking [3], and so on.
Over the past decades, traditional algorithms, including multi-scale transformation [4], sparse representation [5], subspace decomposition [6], optimization model [7], hybrid-based [8], and other methods [9], have been proposed for infrared and visible image fusion. Although these methods achieved great processes and can fulfill the requirements of most scenarios, they still exhibit certain limitations. On the one hand, these methods usually develop the same mathematical model to indiscriminately extract image features, and rarely consider the inherent distinctiveness of different modality images, which limits the fusion performance improvement. On the other hand, the fusion rules or activity level measurement need to be manually designed. This strategy potentially compromises the objectivity and reliability of image fusion output, which is unsuitable for some complicated scenarios and subsequent decision-making applications.

In recent years, deep neural networks have experienced rapid adoption in the field of image fusion. Generally, the mainstream deep learning-based models include autoencoder (AE)-based [10], [11], convolutional neural network (CNN)-based [12], [13], Transformer-based [14], [15], and generative adversarial network (GAN)-based [16], [17] methods. AE-based methods employ the encoder-decoder framework to extract and reconstruct features, and design a fusion layer to integrate their respective features. Nevertheless, the fusion strategies are still hand-crafted. CNN-based methods usually concatenate source images in the input stage as an image-level framework or integrate features in the fusion stage to form a feature-level framework. Different to CNN, Transformer-based methods employ a self-attention mechanism to model the long-range dependencies, and achieve state-of-the-art (SOTA) performance. However, the above methods are non-generative fusion schemes, which cannot take advantage of strong generative ability. Image fusion as a generative task, GAN-based methods employ adversarial training to constrain the same distribution of fused output and source images. Nevertheless, the tradeoff between generator and discriminator is difficult to follow during training, which presents a challenge for achieving controlled generation. Moreover, unexplainable mechanism and mode collapse of GANs seriously affect the fusion quality.
Recently, denoising diffusion probabilistic models (DDPM) [18] have demonstrated remarkable advances in generating hopeful synthetic samples. Unlike the existing GAN-based methods, the generation process of DDPM is interpretable as it relies on denoising principles, which can effectively achieve controllable high-quality and high-fidelity generation. Furthermore, DDPM does not require discriminative constraints, thereby avoiding the common issues of unstable training and mode collapse often encountered by GANs. Specifically, Zhao et al. [19] formulated fusion task into an unconditional generation problem, and integrated the hierarchical Bayesian model in likelihood rectification. Yue et al. [20] constructed the multi-channel distribution based on diffusion model to extract complementary information for high color fidelity fusion tasks. Although these methods achieve surprising fusion performance, some drawbacks still need to be addressed. On the one hand, due to the posterior sampling procedure, their fusion models usually require extensive storage space and long inference times. On the other hand, these methods only leverage the generative capacity of diffusion mode while failing to consider the contextual interactions of multi-modality images, resulting in limited fusion performance.
To address these issues, we introduce a simple yet strong fusion baseline, namely diffusion model guided cross-attention learning network, termed as DMFuse. In the first training stage, to alleviate the strains on storage space and inference process, we directly compress the quadruple channels of diffusion UNet, and train a robust model using the MS-COCO dataset [21]. Because this dataset encompasses diverse object categories, abundant image data, and various visual scenarios, it aids in bolstering the generalization ability of the diffusion model for fusion tasks, even when model parameters are compressed. In the second training stage, instead of relying on mainstream convolution operations or self-attention mechanisms, we employ the pre-trained diffusion model as an autoencoder to generate the diffusion features, which can seamlessly transfer its high-quality generation ability to the subsequent fusion network. In addition, we develop a cross-attention interactive fusion module to aggregate the diffusion features of infrared and visible images, which can model the global dependencies from local contexts and improve the complementary characteristics of different modalities. Finally, a multi-level decoder network is proposed to progressively reconstruct the fused output.
To demonstrate the superiority of the proposed DMFuse, we compare it with the CNN-based method, i.e., U2Fusion [12], Transformer-based method, i.e., YDTR [15], and diffusion model-based method, i.e., DDFM [19]. Figure 1 illustrates a schematic diagram for comparison. U2Fusion and YDTR are non-generative schemes that focus on modeling local features and local-global dependencies, respectively. Although the fused results preserve visible details well, they fail to retain the infrared target brightness. DDFM formulates the fusion task into unconditional generation and samples a fusion image from the posterior distribution. However, the generated result still exhibits limited preservation of target brightness. In contrast, the proposed model can simultaneously enable rich detail preservation and considerable intensity control. In summary, the main contributions of our work are threefold.
We introduce a novel diffusion model guided fusion baseline. The pre-trained diffusion model is employed as an encoder to provide a powerful distribution mapping, thereby grafting its generation ability for fusion tasks.
We develop a cross-attention interactive fusion module to model the global dependencies from local diffusion features, thus effectively strengthening and integrating the complementary characteristics of different modalities.
We train a more efficient and robust diffusion model with different strategies. Extensive experiments demonstrate that DMFuse achieves SOTA fusion performance as well as competitive operational efficiency.
The rest of this paper is schemed as follows. Section 2 mainly discusses the non-generative and generative fusion schemes. In Section 3, the framework of the proposed model is elaborated. In Section 4 and Section 5, experimental comparisons and relevant conclusions are given, respectively.
This section provides an overview of the related work that is closely related to the proposed method. From a generative standpoint, we can roughly categorize the existing works as non-generative and generative fusion schemes.
AE-based methods generally follow the traditional framework, and employ a pre-trained encoder-decoder network to extract and reconstruct features. For example, Li et al. developed DenseFuse [10] and NestFuse [11] where dense blocks and nest connections are introduced to enhance feature representation. Zhao et al. [22] presented AUIF in which the traditional optimization model was mapped to a trainable neural network by the algorithm unrolling. To improve fusion performance, Jian et al. elaborated SEDRFuse [23] and DDNSA [24] in which attention-based fusion strategies are employed to better strengthen the complementary characteristics of different modalities. However, these methods need to design the fusion strategies manually, restricting their practical applications.
CNN-based methods usually propose image-level or feature-level frameworks to implement unsupervised learning. Typically, Xu et al. [12] introduced U2Fusion, which concatenated source images as an input, and employed a pre-trained VGG-16 network to measure information preservation degree for supervising the similarity constraint. Li et al. [13] elaborated RFN-Nest, which proposed a two-stage training strategy to train the encoder-decoder framework and fusion network, respectively. They also presented LRRNet [25], which formulated the fusion task as optimized decomposition and network learning problems. An et al. [26] introduced MRASFusion, which designed a residual attention fusion module for feature interactions. Chen et al. developed IVIFD [27] for a joint fusion and detection task. Zhu et al. [28] proposed MGRCFusion, which utilized a multi-scale group residual convolution module to exploit finer deep-level features.
Transformer-based methods mainly depend on the self-attention mechanism to model the global dependencies and maintain long-range context. Pang et al. [14] introduced SDTFusion, which employed dense Transformer blocks to extract the global features. Tang et al. presented YTDR [15] and DATFuse [29], which proposed a serial CNN-Transformer architecture to aggregate local and global features. Ma et al. [30] elaborated SwinFusion, which designed self-attention and cross-attention units to integrate intra- and inter-domain interactions. Tang et al. [31] developed a multi-branch network based on CNN and Transformer to extract the local and global information for multi-modality fusion. In addition, Liu et al. [32] introduced SegMiF, which proposed a multi-interactive framework for the joint tasks of fusion and segmentation.
The aforementioned methods tend to design efficient network structures [10], [11], [26], [28], novel fusion rules [23], [24], different training strategies [13], [22], [25], [27], long-range modeling [14], [15], [30], [31], and multi-task learning [12], [32]. The core is to employ convolutional or self-attention operations to discriminate model local, global, or joint features. However, due to the lack of ground truth and the fact that these methods are non-generative fusion schemes, the lack of in-depth exploration of generative models limits the potential fusion performance improvement.
GAN-based methods generally apply adversarial training to generate a fused image that follows the same distribution as the source images. Ma et al. [16] firstly devised FusionGAN, which employed a generator to obtain the fused image, and used a discriminator to determine whether the fused output has a similar distribution to source images. Meanwhile, they also introduced TarDAL [33], which designed a target-aware dual adversarial learning network for the joint problems of fusion and detection. Wang et al. presented ICAFusion [34], CrossFuse [35], and FreqGAN [36], which introduced attention mechanisms and frequency information to implement feature interaction and iterative optimization. These methods focus on the design of flexible networks, such as generator architecture [16], attention mechanism [34], [35], and multi-task learning [33]. However, the GAN-based methods suffer from unexplained mechanism, unstable training, and mode collapse, which adversely impacts the fusion quality.
Diffusion-based methods formulate fusion tasks as a conditional generation problem within the diffusion sampling framework, which can overcome the common problems of GANs. For example, Yue et al. [20] presented Dif-Fusion, which directly introduced the multi-channel data construction into a diffusion process, and achieved a fused output with high color fidelity. Zhao et al. [19] devised DDFM, where an unconditional generation module and a conditional likelihood rectification module are designed to deliver favorable results. These methods leverage the generative ability of diffusion mode, but present significant time-consuming issues in terms of storage space and inference processes, and do not take into account the contextual interactions. Different from them, the proposed model employs a more efficient and robust diffusion model to graft its high-quality generation ability for fusion tasks. Meanwhile, we design a cross-attention interactive fusion module to strengthen the complementary characteristics of different modalities. Therefore, the proposed model achieves superior fusion performance while requiring less computational costs.
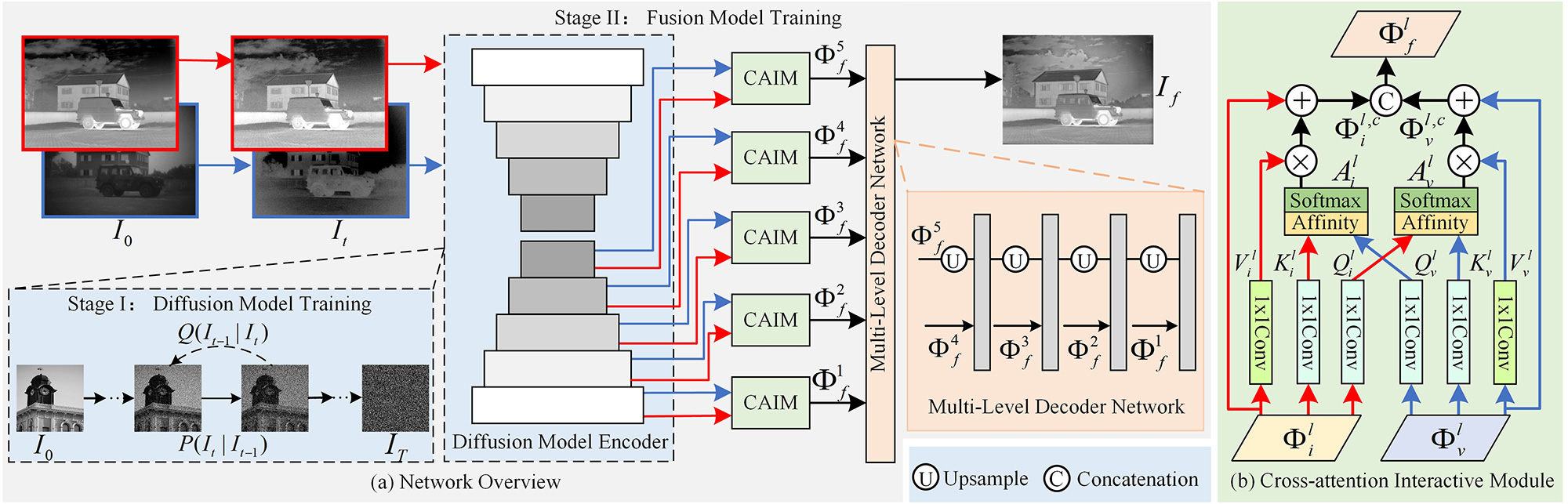
In this section, we elaborate on the overall workflow of the fusion baseline, including network overview, cross-attention interactive fusion module, and loss function.
As depicted in Figure 2(a), DMFuse consists of three core components, i.e., pre-trained diffusion model, multi-level decoder, and cross-attention interactive fusion module. Given the input infrared and visible images , the forward process of the diffusion model gradually adds Gaussian noise to the input image , and generates noisy image and its distribution at timestep .
After that, we employ the diffusion model encoder to extract multi-level diffusion features of infrared and visible images, termed as and , and fed them into cross-attention interactive fusion module (CAIM), which is shown in Figure 2(b), to generate the fusion features . Finally, a multi-level decoder network is proposed to reconstruct the final fused outputs, which is formulated by Eq.(1).
where and denote the convolutional and upsampling operations. [] indicates the channel concatenation. Next, we will describe the training process of the diffusion model.
The diffusion model implements the variational inference on a Markovian chain, which includes both forward and backward processes. In the forward process, Gaussian noise is incrementally added to the input image until it is fully destroyed within timesteps. By using the reparameterization trick, the simplified distribution of noisy image at each time step can be directly derived from the input image sampling, which is formulated by Eq.(2).
where is a Gaussian distribution, denotes the variance schedule, and , . represents the standard normal distribution.
Technically, the forward process aims to degrade the image data into an isotropic Gaussian distribution by adding noise. On the contrary, the backward process attempts to eliminate the degradation by a denoising network. During the backward process, a series of denoising operations are performed on the noisy image to obtain back . The corresponding distribution of given can be formulated by Eq.(3).
where and are the mean and standard deviation of .
During the training phase, the noise and the timestep are sampled from the standard normal distribution and the uniform distribution, respectively. The noisy image and the timestep are fed into the denoising network , which is a UNet framework. A simple supervised loss can be formulated by Eq.(4).
The diffusion model consists of a five-level U-Net framework, where the decoder backbone is subjected to randomly sampled noise levels to reconstruct the denoised diffusion features. Therefore, we employ the diffusion model as an encoder to extract multi-level diffusion features from noised infrared and visible images. The formulation is expressed by Eq.(5).
where denotes the diffusion model encoder operation.
In particular, the diffusion model encoder is capable of generating more robust feature representations over the CNN encoder. Additionally, to accelerate inference process of the diffusion model, we compress the channel numbers of each layer to 1/4 of the original. A comprehensive discussion regarding the diffusion model encoder and its training strategies will be presented in the ablation study.
After training the diffusion model, we employ it as an encoder and freeze its parameters while proceeding to train the fusion network. The multi-level diffusion features are then utilized as input for the cross-attention interactive fusion modules, facilitating global interactions. Inspired by CCNet [37], we aggregate contextual dependencies together for all pixels in its criss-cross path. More importantly, we exchange the query features of different modalities to capture their interactive cross-attention maps, which effectively strengthens their complementary characteristics to promote better fusion performance.
As shown in Figure 2(b), given the diffusion features and , we first perform two convolution layers with 11 filters to achieve their query and key features, i.e., and , where and represent the height and width of feature maps, and the channel is less than for dimension reduction. After that, we exchange the feature maps and of different modalities and further generate their respective cross-attention maps and via Affinity opertions. Taking the infrared modality as an example, at the position n within the spatial dimension of infrared features , we can achieve a vector from itself and a set from visible features , which are in the same column or row with position n. Then, the Affinity opertions can be formulated by Eq.(6) and Eq.(7), respectively.
where denote the degree of correlation between infrared and visible features and their reverse order, , stand for the th element of and , , and , . Then, we employ a softmax layer on and across the channel dimension to calcuate the cross-attention maps and , respectively.
Subsequently, another convolution layer with filters is used for the diffusion features , to generate for feature adaptation. Similarly, we can also obtain the vetors and sets at their spatial position n. Thus, we apply an multiplication operation and a skip connection to collect the contextual information of different modalities, which are expressed by Eq.(8) and Eq.(9), respectively.
where and denote the global cross-attention features of infrared and visible modalities. Finally, we concatenate them to generate the fusion features .
To train the fusion model, we employ structural similarity (SSIM) loss, intensity loss, and gradient loss to supervise the network. Concretely, SSIM loss () is used to constrain the structural similarity between fused result and source images , , which is defined by Eq.(10).
where denotes the structural similarity operation. and are set to 0.5.
Meanwhile, the intensity loss is designed to maintain more valuable pixel intensity information from source images, and its formalization is expressed by Eq.(11).
where denotes the average operation.
Moreover, the gradient loss is proposed to transfer as many details as possible from different modalities, which is formulated by Eq.(12).
where is the Sobel gradient operator. and stand for the maximum and L1-norm operations, respectively.
Finally, the total fusion loss can be expressed by Eq.(13).
where , and are the hyperparameters, which are used to balance the three losses.

This section introduces the correlative experimental configurations and comparative validations of fusion tasks and downstream applications. The ablation studies are also deeply discussed.
In the training phase, we first train the diffusion model on the MS-COCO benchmark. This dataset includes more than 80000 complex scenario images. The training parameter settings are consistent with DDPM [18]. After that, we then train the fusion model on the TNO benchmark. To augment the training dataset, we take a sliding step of 12, crop the images into patches of size 256 256 and normalize their gray value range to [-1, 1]. This process yields a total of 18813 patch pairs for training. The batch size and number of epochs are set to 4 and 16, respectively. The model is optimized using the Adam optimizer. In the loss function, we empirically set , , and to 1, 4, and 20. Additionally, the pre-trained diffusion model generates diffusion features at three different time steps, i.e., 5, 50, and 100. All experiments are conducted on a platform equipped with an NVIDIA GeForce GTX 3090, Intel I9-10850K, and 64 GB memory.
In the testing phase, we employ the TNO 11, M3FD 22 and Harvard MIF 33 benchmarks, and select 25, 40 and 50 image pairs to evaluate the effectiveness and superiority of the proposed model. In addition, seven SOTA competitors, including the non-generative schemes, U2Fusion [12], RFN-Nest [13], YDTR [15], and DATFuse [29], the generative schemes, FusionGAN [16], Dif-Fusion [20], and DDFM [19], are selected to compare with the proposed model. Moreover, we also employ eight metrics, namely entropy (EN) [38], standard deviation (SD) [39], phase congruency (PC) [40], feature mutual information based on pixel (FMIp) [41], Qe [42], Qabf [43], multi-scale structural similarity (MS-SSIM) [44], and visual information fidelity (VIF) [45] for quantitative verification. In the follow-up experiments, the red bold and blue underline indicate the optimal and suboptimal values, respectively.

We first conduct experiments on the TNO benchmark to showcase the effectiveness of the proposed DMFuse. Three representative examples, namely Nato_camp, Street, and Kaptein_1123, are selected for subjective description, and their contrastive results are shown in Figure 3. The CNN-based methods, i.e., U2Fusion and RFN-Nest, focus on modeling local features using image-level and feature-level frameworks, respectively. Although they manage to preserve visible details, they tend to lose brightness in the infrared targets. The Transformer-based methods, i.e., YDTR and DATFuse, attempt to integrate local and global features to achieve better visual effects. However, they still struggle to effectively control the brightness information. FusionGAN aims to retain target brightness but sacrifices visible detail information potentially due to unstable training. DDFM integrates inference solution and diffusion sampling within the same iterative framework to generate fusion images directly, but it fails to effectively combine thermal radiation information. Dif-Fusion constructs a multi-channel data distribution and yields similar results to the proposed model. In comparison, the proposed model effectively preserves rich details and control considerable intensity.
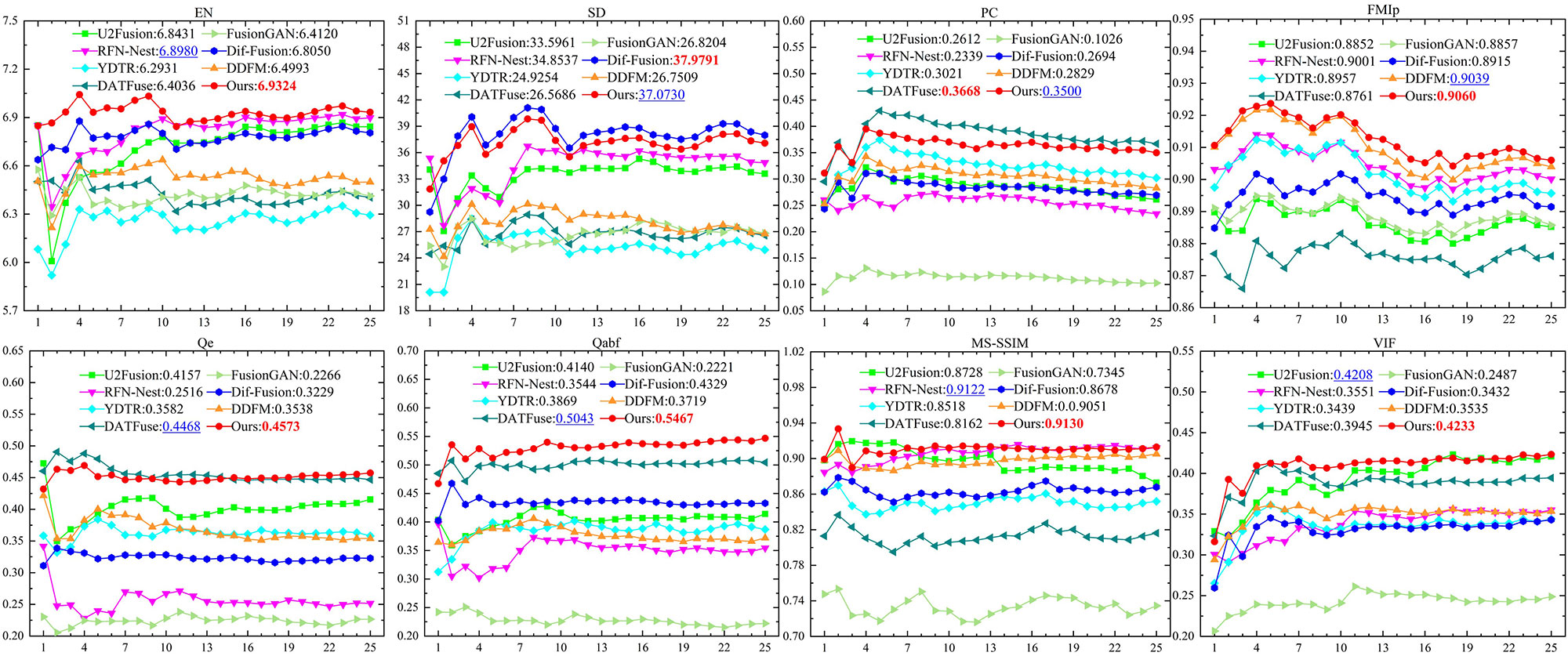
Subsequently, eight metrics previously mentioned are used for the quantitative evaluation of fusion performance, and the comparable results are presented in Figure 4. The proposed model is described by the red dotted line. Obviously, the proposed model demonstrates excellent performance across all metrics. The corresponding EN, FMIp, Qe, Qabf, MS-SSIM, VIF rank first, and SD, PC rank second, which follow behind Dif-Fusion and DATFuse, respectively. The optimal Qe, Qabf, and MS-SSIM indicate that the proposed model can transfer edge, gradient, and structural information into the fused results from source images. The optimal EN, FMIp, and suboptimal PC demonstrate that the proposed model can preserve significant details and meaningful information. The optimal VIF and suboptimal SD reveal that the proposed model has better visual performance and contrast definition. Quantitative experiments confirm its superiority, aligning with the above qualitative observations.
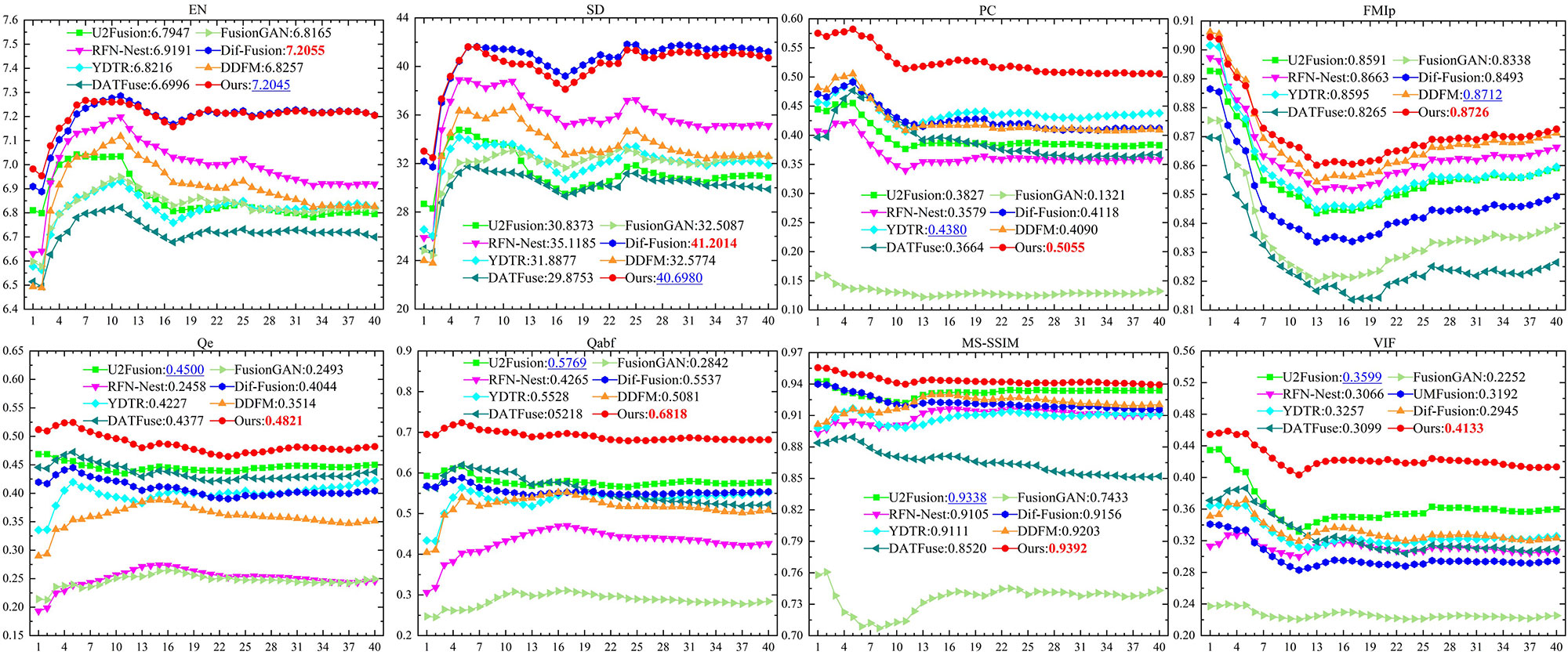
We further carry out experiments on the M3FD benchmark, and compare the proposed model with other competitors to verify its generalization ability. For the color image fusion, we first transfer the RGB visible image to the YCbCr color space, and return it after the Y channel is integrated with the infrared image. Figure 5 gives the subjective comparison results of three examples, namely 03878, 03989, and 00762. The proposed method offers significant advantages in terms of detail preservation and intensity control. For the salient pedestrian targets, the proposed model preserves high-brightness target characteristics and distinct contour edges. Meanwhile, for the background details, such as trees, windows, and handrails, it also gets the clearest detail description. In addition, Figure 6 describes the objective comparison results. The proposed model achieves the top ranking for all the metrics except for EN and SD, which are in arrears of Dif-Fusion. Both subjective and objective experiments demonstrate that the proposed model yields promising fusion performance and transcends other SOTA competitors.
| Models | EN | SD | PC | FMIp | Qe | Qabf | MS-SSIM | VIF |
|---|---|---|---|---|---|---|---|---|
| U2Fusion [12] | 3.7566 | 33.8763 | 0.3735 | 0.8579 | 0.3093 | 0.3776 | 0.8552 | 0.2489 |
| RFN-Nest [13] | 4.1351 | 56.6246 | 0.2396 | 0.8616 | 0.2229 | 0.1983 | 0.8928 | 0.2256 |
| YDTR [15] | 4.1527 | 37.6520 | 0.4553 | 0.8648 | 0.3990 | 0.4267 | 0.8811 | 0.2597 |
| DATFuse [29] | 4.2113 | 54.9562 | 0.4360 | 0.8531 | 0.5040 | 0.6113 | 0.9262 | 0.2605 |
| FusionGAN [16] | 4.2226 | 44.7076 | 0.1375 | 0.8496 | 0.2095 | 0.1662 | 0.8079 | 0.1708 |
| Dif-Fusion [20] | 4.7231 | 60.7802 | 0.4513 | 0.8660 | 0.4644 | 0.6354 | 0.9559 | 0.2994 |
| DDFM [19] | 3.8027 | 56.4941 | 0.4622 | 0.8796 | 0.4725 | 0.6363 | 0.9507 | 0.3288 |
| Ours | 5.6969 | 61.8903 | 0.5438 | 0.8754 | 0.5546 | 0.7154 | 0.9545 | 0.3319 |
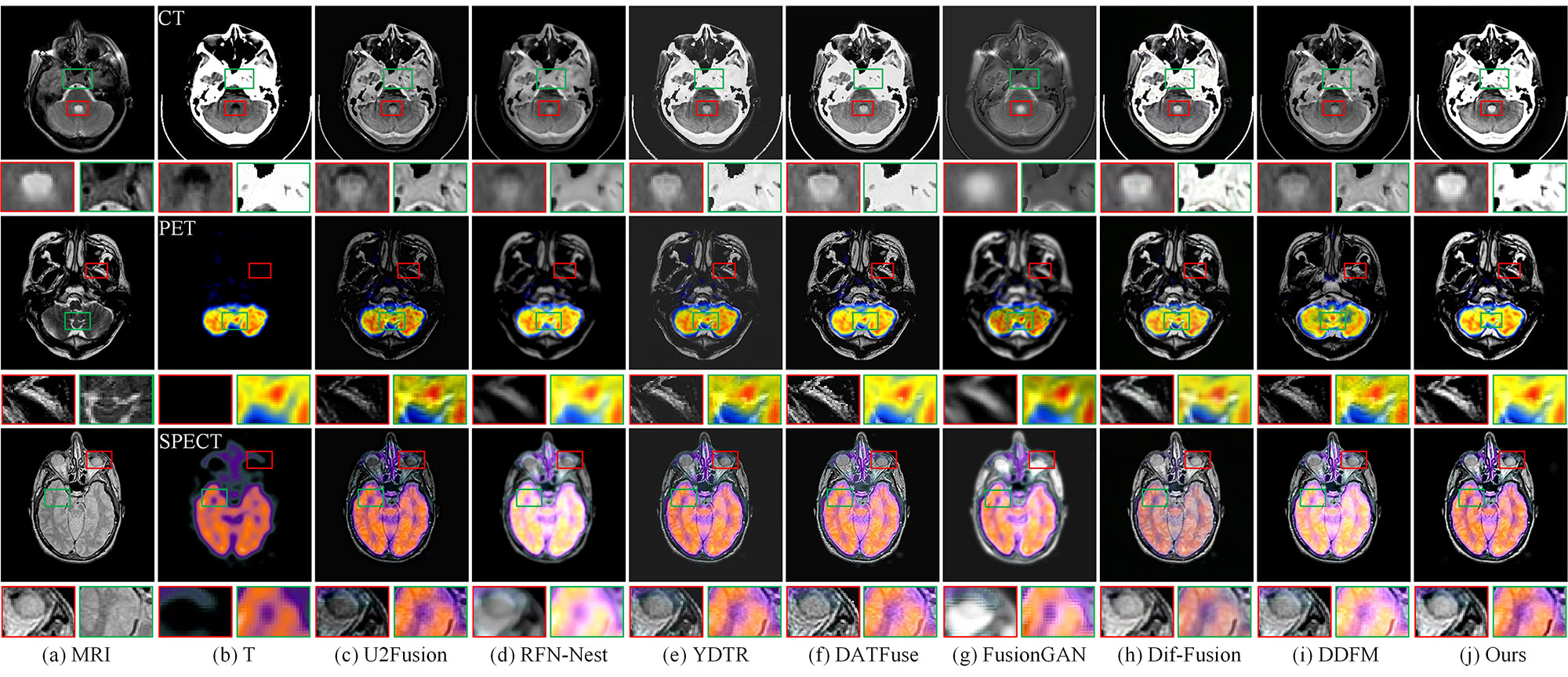
In this section, we conduct experiments on the Harvard MIF benchmark to further verify the generalization of the proposed model. Figure 7 gives the subjective comparison results of three examples, namely MRI_CT_21, MRI_PET_32, and MRI_SPECT_48. Compared with other methods, the proposed model remains effectively the soft tissue texture information presented in MRI images and highlights the areas of high-density contrast enhancement in T images. Table. 1 presents the quantitative results of different fusion methods. Obviously, DMFuse obtains the optimal performance in terms of EN, SD PC, Qe, Qabf and VIF. The metrics FMIp and MS-SSIM rank second, which follow behind DDFM and Dif-Fusion, respectively. Both subjective and objective experiments demonstrate that the proposed model yields excellent performance in the medical image fusion tasks.

In summary, the above experiments on the TNO , M3FD and Harvard MIF benchmarks confirm the superior performance and generalization ability of the proposed model for different lighting and object categories. The main reasons are twofold. On the one hand, we use the MS-COCO dataset to train the diffusion model for more stable performance. More importantly, we employ the diffusion model to guide the fusion network. The diffusion features fully exhibit a strong distribution mapping capacity, and provide extra feature details for fusion tasks. Therefore, the fused results preserve rich details from source images. On the other hand, the designed cross-attention interactive fusion module can effectively implement the global interactions of different modalities. Under the supervision of the loss function, the fusion images achieve better visual effects with high-brightness targets and unambiguous details. As a result, DMFuse makes the fusion image easy to distinguish foreground objects and background edges.
In addition to fusion performance evaluation, we also explore the positive role of image fusion for downstream applications. Specifically, we analyze the effects of other visual tasks, such as object detection and semantic segmentation.
| Methods | [email protected] | mAP@[0.5:0.95] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Person | Car | Bus | Lamp | Motorcycle | Truck | All | Person | Car | Bus | Lamp | Motorcycle | Truck | All | |
| Infrared | 0.783 | 0.870 | 0.921 | 0.665 | 0.760 | 0.855 | 0.809 | 0.551 | 0.671 | 0.780 | 0.359 | 0.506 | 0.671 | 0.590 |
| Visible | 0.716 | 0.869 | 0.920 | 0.790 | 0.790 | 0.864 | 0.825 | 0.478 | 0.701 | 0.796 | 0.471 | 0.543 | 0.689 | 0.613 |
| U2Fusion [12] | 0.774 | 0.883 | 0.925 | 0.784 | 0.774 | 0.867 | 0.835 | 0.549 | 0.717 | 0.799 | 0.474 | 0.547 | 0.701 | 0.631 |
| RFN-Nest [13] | 0.772 | 0.881 | 0.924 | 0.790 | 0.775 | 0.865 | 0.835 | 0.544 | 0.716 | 0.798 | 0.467 | 0.541 | 0.700 | 0.628 |
| YDTR [15] | 0.768 | 0.885 | 0.925 | 0.781 | 0.766 | 0.859 | 0.831 | 0.546 | 0.714 | 0.800 | 0.473 | 0.539 | 0.700 | 0.629 |
| DATFuse [29] | 0.764 | 0.881 | 0.919 | 0.781 | 0.766 | 0.859 | 0.829 | 0.541 | 0.711 | 0.794 | 0.469 | 0.542 | 0.696 | 0.626 |
| FusionGAN [16] | 0.766 | 0.873 | 0.923 | 0.779 | 0.761 | 0.857 | 0.827 | 0.542 | 0.712 | 0.792 | 0.468 | 0.538 | 0.691 | 0.624 |
| Dif-Fusion [20] | 0.775 | 0.886 | 0.926 | 0.796 | 0.772 | 0.858 | 0.836 | 0.549 | 0.716 | 0.787 | 0.473 | 0.538 | 0.702 | 0.628 |
| DDFM [19] | 0.771 | 0.882 | 0.919 | 0.790 | 0.782 | 0.865 | 0.835 | 0.544 | 0.712 | 0.795 | 0.470 | 0.540 | 0.700 | 0.627 |
| Ours | 0.776 | 0.887 | 0.927 | 0.791 | 0.774 | 0.875 | 0.838 | 0.550 | 0.719 | 0.806 | 0.475 | 0.541 | 0.710 | 0.634 |
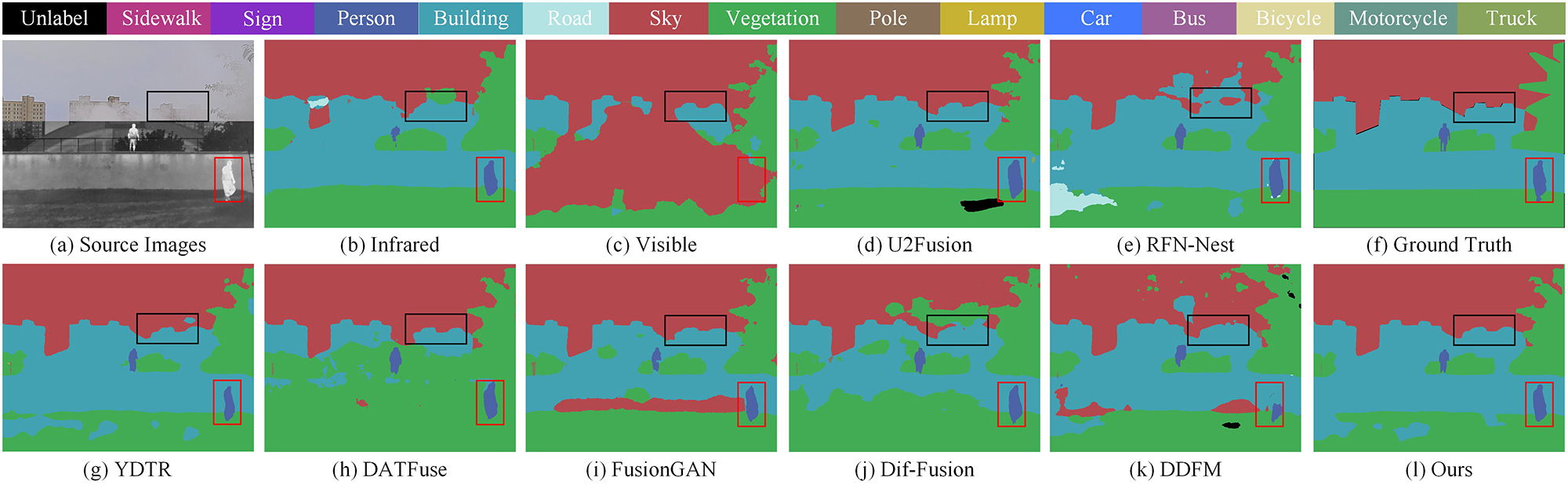
Image fusion for object detection: We first discuss how image fusion affects object detection performance. The experiments are implemented on the M3FD benchmark, which contains 4200 images annotated with 33,603 objects, including six classes, i.e., People, Car, Bus, Motorcycle, Truck and Lamp. The YOLOv5 [46], [47] network is used as the detection baseline, and mean average precision (mAP) is employed as the evaluation metric. Especially, [email protected] represents the precision value at an intersection-over-union (IoU) threshold of 0.5, and mAP@[0.5:0.97] indicates the mean value at IoU thresholds of between 0.5 and 0.97, with steps of 0.05. For a fair comparison, we employ the detection model to source images and fused results.
Figure 8 presents the visual results of object detection. For the representative objects, such as People and Car, the proposed model achieves higher precision values than source images and other competitors, indicating that our fused results are more conducive to object detection tasks. Moreover, the objective comparison results are shown in Table 2. Almost all fusion methods yield good detection performance, and their mAP values are much better than those using only infrared or visible images. Notably, the proposed model outperforms other competitors in terms of mAP value, which has an improvement of 1.09% and 1.77% for [email protected] and mAP@[0.5:0.97]. This indicates that the proposed model can fully discover unique information from different modalities, and offer effective complementary characteristics for the detector to achieve better performance.
| Methods | Road | Sidewalk | Lamp | Sign | Vegetation | Sky | Person | Pole | mAcc | mIoU | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | |||
| Infrared | 83.8 | 79.9 | 51.4 | 30.4 | 70.4 | 12.2 | 79.2 | 54.6 | 84.6 | 74.7 | 95.4 | 90.2 | 84.9 | 63.0 | 46.1 | 24.4 | 74.5 | 53.7 |
| Visible | 84.6 | 82.7 | 66.4 | 32.1 | 57.4 | 33.0 | 83.5 | 65.0 | 93.0 | 81.4 | 93.5 | 91.4 | 84.8 | 41.1 | 63.2 | 37.6 | 78.3 | 58.0 |
| U2Fusion [12] | 91.1 | 85.3 | 56.0 | 39.6 | 72.3 | 31.9 | 86.5 | 57.0 | 86.0 | 82.0 | 96.6 | 92.8 | 87.0 | 56.4 | 70.6 | 35.5 | 80.8 | 60.1 |
| RFN-Nest [13] | 84.7 | 76.3 | 62.1 | 36.3 | 80.4 | 24.9 | 77.8 | 68.3 | 91.9 | 82.2 | 96.7 | 93.9 | 85.6 | 60.8 | 70.1 | 39.2 | 81.2 | 60.2 |
| YDTR [15] | 83.9 | 81.3 | 72.4 | 33.5 | 61.6 | 27.8 | 73.3 | 66.4 | 89.7 | 84.0 | 95.6 | 93.9 | 83.4 | 58.5 | 74.7 | 39.0 | 79.4 | 60.6 |
| DATFuse [29] | 85.1 | 80.0 | 50.3 | 21.7 | 51.4 | 30.0 | 84.0 | 61.5 | 81.7 | 78.4 | 95.6 | 92.6 | 77.9 | 63.1 | 71.8 | 39.4 | 74.7 | 58.3 |
| FusionGAN [16] | 84.8 | 80.0 | 57.8 | 32.6 | 50.4 | 28.5 | 82.6 | 61.5 | 90.4 | 82.3 | 93.7 | 91.3 | 89.2 | 62.6 | 62.1 | 35.7 | 76.4 | 59.3 |
| Dif-Fusion [20] | 83.7 | 80.7 | 66.8 | 26.4 | 46.9 | 32.5 | 78.4 | 68.7 | 87.0 | 80.7 | 96.7 | 92.8 | 86.0 | 64.5 | 66.7 | 35.3 | 76.5 | 60.2 |
| DDFM [19] | 81.2 | 79.9 | 53.7 | 24.0 | 46.1 | 31.0 | 75.4 | 65.3 | 87.7 | 81.2 | 95.1 | 91.8 | 79.0 | 54.6 | 49.1 | 35.1 | 70.9 | 57.9 |
| Ours | 85.2 | 83.9 | 73.0 | 33.6 | 73.4 | 43.6 | 82.7 | 70.3 | 92.3 | 85.6 | 97.3 | 94.5 | 82.6 | 67.5 | 67.2 | 48.2 | 81.7 | 65.9 |

Image fusion for semantic segmentation: We further evaluate the proposed DMFuse with other competitors on the semantic segmentation task. A full-time multi-modality benchmark (FMB) 44 collected from the M3FD benchmark is proposed for the segmentation baseline. The FMB dataset contains rich driving scenes under different lighting and weather conditions, and is labeled into fourteen categories. We select 1120 image pairs as the training set and verify the segmentation performance of different models on the 280 pairs. The relevant experimental configuration is derived from SegMiF [32]. The metrics, accuracy (ACC) and intersection-over-union (IoU) are employed for segmentation evaluation.
The qualitative semantic segmentation comparisons are depicted in Figure 9. For the representative objects and details, such as pedestrians and buildings, single-modality infrared and visible images cannot produce accurate classifications. However, the fusion methods improve the semantic segmentation performance to some extent. This indicates that the complementary characteristics of image fusion facilitate the segmentation accuracy. More importantly, the proposed model effectively classifies objects and scenes with high accuracy, which is closest to ground truth. Table 3 reports the quantitative semantic segmentation comparisons. The numerical results demonstrate the proposed model is ahead of other SOTA competitors in terms of mACC and mIoU. In short, the proposed model can exploit and strengthen the complementary information of different modalities, which generates a positive effect on semantic segmentation.
This section presents several specialized designs incorporated into the proposed DMFuse, and their effectiveness is evaluated through ablation experiments that focus on the model architecture and training strategy. The qualitative and quantitative comparisons are also presented in this section.
| Testing Datasets | Training Datasets | EN | SD | PC | FMIp | Qe | Qabf | MS-SSIM | VIF |
|---|---|---|---|---|---|---|---|---|---|
| TNO Benchmark | TNO | 6.8466 | 35.7474 | 0.3086 | 0.9026 | 0.4073 | 0.5009 | 0.9090 | 0.4154 |
| M3FD | 6.8466 | 34.0896 | 0.3032 | 0.9002 | 0.3936 | 0.4767 | 0.9156 | 0.3901 | |
| MS-COCO (Ours) | 6.9324 | 37.0730 | 0.3500 | 0.9060 | 0.4573 | 0.5467 | 0.9130 | 0.4233 | |
| M3FD Benchmark | TNO | 7.0188 | 36.4068 | 0.2798 | 0.8538 | 0.2723 | 0.4244 | 0.8990 | 0.2786 |
| M3FD | 7.1955 | 40.2199 | 0.3149 | 0.8487 | 0.3697 | 0.5227 | 0.9195 | 0.3068 | |
| MS-COCO (Ours) | 7.2045 | 40.6980 | 0.5056 | 0.8726 | 0.4821 | 0.6818 | 0.9392 | 0.4133 |
| Metrics | EN | SD | PC | FMIp | Qe | Qabf | MS-SSIM | VIF | Params(M) | FLOPs(G) | Time(s) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Original | 6.9135 | 37.6477 | 0.3845 | 0.9106 | 0.4861 | 0.5898 | 0.9150 | 0.4336 | 392.724 | 1516.136 | 74.110 |
| 1/2 | 6.9150 | 37.1946 | 0.3738 | 0.9084 | 0.4794 | 0.5754 | 0.9125 | 0.4296 | 98.680 | 382.052 | 6.403 |
| 1/4(Ours) | 6.9324 | 37.0730 | 0.3500 | 0.9060 | 0.4573 | 0.5467 | 0.9130 | 0.4233 | 24.967 | 106.584 | 2.624 |
| 1/8 | 6.9402 | 36.9426 | 0.2405 | 0.8899 | 0.3849 | 0.4181 | 0.9036 | 0.3786 | 6.433 | 35.967 | 2.163 |
| Models | EN | SD | PC | FMIp | Qe | Qabf | MS-SSIM | VIF |
|---|---|---|---|---|---|---|---|---|
| w/o Dif | 6.8480 | 35.1861 | 0.3196 | 0.8975 | 0.4735 | 0.4862 | 0.8830 | 0.4228 |
| w/o CAIM | 6.8574 | 35.9839 | 0.3155 | 0.8886 | 0.3477 | 0.4902 | 0.8985 | 0.3439 |
| Ours | 6.9324 | 37.0730 | 0.3500 | 0.9060 | 0.4573 | 0.5467 | 0.9130 | 0.4233 |
Training on Different Datasets: To assess the generalization performance of the diffusion model, we train it on the different datasets, including TNO, M3FD, and the proposed MS-COCO. From the results of Figure 10 (c) and (d), the fusion images of TNO and M3FD trained models exist in detail confusion and color degradation to a certain extent. The quantitative verification is compared in Table 4. A typical phenomenon is that a fusion model trained by a certain dataset maintains superior performance on the corresponding testing. Overall, the proposed method achieves more stable and outstanding performance on different testing datasets.
Channel in Diffusion UNet: We compress the channel numbers of diffusion UNet at each layer to 1/4 in our fusion model, and compare it with other competitive models, i.e., original parameters, 1/2, and 1/8. Noting that we omit the qualitative descriptions because their results are similar. Table 5 shows the quantitative validations on the TNO benchmark. It can be observed that the fusion performance decreases with the reduction in channel numbers, while the model parameters and operation efficiency exhibit an opposite trend. When the channel parameter is reduced to 1/8, the performance becomes comparable to other fusion methods, such as Dif-Fusion and DDFM. In conclusion, the proposed model suggests adopting 1/4 channel parameters to achieve a better balance between fusion performance and computational efficiency.

Verification of Each Component: We employ the diffusion model to extract generative features and develop a cross-attention interactive fusion module to perform the global interactions. To verify their effectiveness, we propose an UNet-style CNN encoder to replace the diffusion model encoder and utilize addition operation instead of CAIM, respectively. As shown in Figure 10 (e) and (f), the fusion images without the diffusion model, termed w/o Dif, lose some target brightness and meaningful details, while the fused results without CAIM, termed w/o CAIM, have limited visual effects. Meanwhile, we visualize the feature maps of diffusion model encoder and CNN encoder (referred to as w/o Dif) in Figure 11. The diffusion features (the first row) demonstrate obvious advantages over CNN features (the second row) in the characterization of infrared salient targets and visible typical details. In addition, the quantitative results, as shown in Table 6, indicate that the proposed model achieves all the optimal values except for Qe, which is behind w/o Dif. The experiments prove that both diffusion model and CAIM are beneficial to fusion performance improvement.
| Methods | Params.(M) | FLOPs(G) | Time(s) | |
|---|---|---|---|---|
| TNO | M3FD | |||
| U2Fusion [12] | 0.659 | 43.17 | 1.722 | 4.646 |
| RFN-Nest [13] | 7.524 | 111.1 | 0.235 | 0.864 |
| YDTR [15] | 0.107 | 20.58 | 0.201 | 0.771 |
| DATFuse [29] | 0.011 | 1.185 | 0.019 | 0.047 |
| FusionGAN [16] | 1.314 | 57.09 | 0.513 | 0.988 |
| Dif-Fusion [20] | 434.2 | 726.1 | 4.820 | 17.21 |
| DDFM [19] | 988.3 | 2946 | 59.18 | 162.1 |
| Ours | 24.96 | 106.6 | 2.624 | 5.342 |
We also conduct experiments to evaluate the operational efficiency of different methods, including training parameters (Params.), floating-point operations per second (FLOPs), and runtime (Time). Table 7 presents their computational complexity. Note that the computation of FLOPs is implemented by a testing image with the size of 256256. Compared with the diffusion-based methods, the non-generative fusion schemes, including U2Fusion, RFN-Nest, YDTR, DATFuse, and the GAN-based method, i.e., FusionGAN, have a significant advantage in terms of training parameters, FLOPs, and runtime. The main reason is that the diffusion model requires many iteration steps and consumes massive computational resources. However, since we train a more efficient model by compressing quadruple channels of diffusion UNet, the proposed model has higher operational efficiency than Dif-Fusion and DDFM, indicating the effectiveness of model training.
The diffusion model showcases powerful generative capabilities and has manifested outstanding performance in the domain of image fusion. Nevertheless, its computational inefficiency constitutes a significant challenge because of the large quantity of iterative steps and the complexity of the calculations. These factors lead to a slow diffusion process, which restricts its applicability in scenarios demanding low computing resources. In future works, we aim to tackle these challenges by exploring optimization strategies such as sampling optimization [48] to reduce the number of iteration steps and latent space transformation [49] to streamline computations. These efforts will concentrate on enhancing computational efficiency while maintaining or improving the quality of the fused results.
This paper presents DMFuse, a novel diffusion model-guided cross-attention learning network, designed for infrared and visible image fusion. Unlike existing methods, the proposed model involves training a lightweight diffusion model to serve as an autoencoder, effectively integrating its high-quality generative capability into the fusion tasks. Moreover, we develop a cross-attention interactive fusion module that facilitates global interactions, strengthening the complementary characteristics of different modalities. We evaluate the performance of DMFuse against seven SOTA methods on TNO, M3FD and Harvard MIF benchmarks. The experimental results validate the proposed model achieves predominant fusion performance and competitive computational efficiency. Furthermore, DMFuse exhibits positive implications for downstream applications, including object detection and semantic segmentation. In future work, we will explore the integration of diffusion models with large language models (LLMs) [50], introducing text descriptions as a semantic guide to further enhance the quality of the fused images.
 Copyright © 2024 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2024 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/