


Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Google introduced the concept of Knowledge Graphs in 2012, significantly enhancing the ability to manage, understand, and organize the vast amounts of data in the world. This advancement is attributed to its structured triplet form, which effectively represents entities, their attributes, and the relationships between them [1]. Over the last many years, knowledge graphs have played an increasingly important role in various perception tasks [2], especially bringing vitality to areas like intelligent question answering [3], software development [4], knowledge alignment [5], and intelligent recommendation [6]. There are many large-scale knowledge graphs, such as DBPedia [7], Freebase [8], NELL [9], and WordNet [10], which are widely used in numerous knowledge-aware artificial intelligence applications. Although knowledge graphs have high application value, they suffer from incompleteness due to the large amount of valuable knowledge that is implicit or missing. Data shows that in current large knowledge graphs, some common basic relationships (such as birth rate, nationality, parents, etc.) are missing over 70% of the time, and there is considerably little evidence of connections with reduced usage rates [11]. To increase the knowledge graph’s scalability, Knowledge Graph Completion (KGC) attempts to predict and complete the missing triplets [12].
The main difficulties and challenges currently faced include: first, in the face of complex knowledge graph structures, existing methods cannot effectively reflect the neighborhood information of entities in the entity embedding representations. Second, for the task of knowledge graph completion, the close relationship between the entity neighbourhood information and relationship paths in the knowledge graph plays a crucial role, but current methods fail to fully integrate them. Finally, due to the differences in the training dataset distribution, which is significantly different from the real world, existing completion methods have poor generalization ability and cannot cope with the rapidly changing real world. To solve the above challenges, this paper proposes a knowledge graph completion model that integrates relationship paths and entity neighbourhood information (RPEN-KGC). The specific contributions of this paper are as follows:
The proposed RPEN-KGC model integrates entity neighbourhood information and relationship paths in the knowledge graph, and uses semantic feature information from the relationship paths to infer more potential semantic information in the semantic space.
The RPEN-KGC model uses a generator-adversarial network-based reasoning engine to train adversarial on the generated samples and expert samples formed by random walks, ultimately obtaining reasoning paths for the completion task and effectively improving the model’s robustness to noisy data.
To provide more diverse expert paths to the generator-adversarial network, an unsupervised sampler is used to collect richer relationship paths as expert paths based on the feature environment of each entity.
Section 2, review existing studies, highlight contributions, identify research gaps, and in section 3, explain framework addressing gaps with models, diagrams, and algorithms. In section 4, present experiments, evaluate performance, compare results, analyze findings, and in section 5, conclude findings, discuss implications, limitations, and suggest future work.
To solve the data sparsity issue in knowledge graphs of artificial intelligence of social things, knowledge graph completion uses the existing information to fill in missing facts. This study summarizes previous studies and classifies the known approaches for completing knowledge graphs into three groups: those that rely on translation, those that rely on semantic matching, and those that rely on relationship paths.
By encoding things into low-dimensional embeddings and the relationships between them as translation vectors, translation-based algorithms provide great performance with low complexity in knowledge graph of artificial intelligence of social things. To determine whether a triplet is accurate, these methods usually use distance-based scoring and establish a translation scoring system based on dependencies. As the foundation of translation models, the TransE model [13] can outperform most conventional methods while maintaining a reasonable level of efficiency by translating entities and their relationships into a continuous low-dimensional vector space. In this space, the tail entity is thought of as the product of translating the head entity by the relationship vector. Nevertheless, when it comes to modeling complicated relationships, the TransE model falls short due to its oversimplification, which restricts it to 1-to-1 relationships. One example is the TransH model [14], which uses an extra mapping vector for every relationship. This allows it to translate things by assigning them to hyperplanes of the relationship. Convolutional neural networks (CNNs) are used to build the discriminator because of their great performance in semantic feature extraction. This helps to improve the semantic distinction between the expert paths and the generated paths. Semantic feature extraction is carried out after the generated paths and expert paths are packaged as path bundles for every entity pair. The PKICLA model determines the probability score for the validity of the candidate triplets by extracting semantic features from several routes using CNN and Bi-LSTM. By first building entity and relationship embeddings in their own vector spaces, the TransR model [15] can then translate these into their respective relationship spaces. To improve computational performance, the TransD model [16] replaces matrix multiplication with vector multiplication, embeds two vectors for each entity, and assigns a new relationship mapping matrix to each entity, all of which are advancements over TransR. In general, approaches based on translation, which depend on internal structural information, are straightforward, efficient, and frequently utilized as a base for expanding models. These methods are employed to solve knowledge graph completion challenges.
The conventional approach to knowledge prediction using semantic matching involves calculating a scoring function that estimates the probability of new facts emerging from existing data by measuring the possible semantic similarity of entities and relationships in vector space. Binary relationship data is intrinsically structured, as the RESCAL model [17] illustrates via a third-order tensor decomposition. An entity’s possible semantics are represented by a vector, and the interactions between these vectors are simulated using a relation matrix. By substituting a diagonal matrix for the dense one in RESCAL, the DistMult model drastically lowers the model’s computing parameters. While the DistMult model is capable of handling asymmetric relations in the knowledge graph, this is because the product operator on real numbers has the property of being balanced. Recognized as the pioneer in handling symmetric and antisymmetric relations using complex-valued embeddings in complex space, the ComplEx model [18] represents each embedding with two vectors, one for real and one for imaginary components. When it comes to representing entities and relationships, traditional semantic matching-based models have limitations due to their exclusive focus on the intrinsic feature information of the triplet and their disregard of the rich According to research on semantic matching approaches, neural networks can accurately model the semantic links between individual items and intelligently capture their semantic properties, which in turn improves the reasoning accuracy of the model. A two-dimensional convolutional network is employed by the ConvE model [19] to anticipate new information in the knowledge graph of artificial intelligence of social things by combining local spatial aspects of entities and relationships from various viewpoints. The main difference between ConvE and the ConvKB model [20], which was presented later, is that the latter employs a 1D convolutional network to extract global associations along the same dimension of the input triplet matrix, rather than a 2D one. This allows ConvKB to represent each triplet as a 3D matrix. To characterize the possible semantic linkages along routes of any length, the PATH-RNN model [21] applies composite functions recursively using a recurrent neural network., generating corresponding path vectors to infer missing relations in the knowledge graph of artificial intelligence of social things. The Single-Model model, based on PATH-RNN, combines relationships, entities, and entity types to effectively improve the model’s reasoning performance.
In knowledge graphs, there are many relationship paths between entity pairs that represent their semantic relationships. One reason knowledge graph completion has progressed is because relationship path-based methods have become more popular; these pathways reflect the intricate reasoning patterns between relations in the knowledge graph of artificial intelligence of social things. Learning relationship paths for reasoning in knowledge graphs were initially introduced by the PRA model. It takes a pair of entities as input, uses a classifier to find out if the relationship you’re asking about actually exists, and then builds relationship pathways between them using random walks. By including multi-path relationship reasoning and utilizing a resource allocation technique to apply weights to the many routes, the PTransE model improves the efficiency of the translation-based model’s predictions. In contrast to the PRA algorithm’s random walk technique, the DeepPath model searches for reasoning paths in the knowledge graph using reinforcement learning, enabling it to regulate the nature of the search. The MINERVA model [22] is very similar to DeepPath in that it uses LSTM networks to define relationship paths and uses path validity as the only measure of success for rewards. By encoding the historical information of the searched paths in an RNN and mapping it into the reinforcement learning state and action space, the M-Walk model [23] improves reasoning accuracy through inferring paths and generating more positive rewards through an improved Monte Carlo Tree Search (MCTS). The DIVINE model can adaptively adjust the reward function to optimize model performance based on different environments. These models only consider single-path reasoning and ignore the semantic similarity between multiple paths. Given the scenario described above, an emergent entity’s current neighbors are taken into consideration as an additional kind of input for inductive models. Hamaguchi et al. [24] suggest using a Graph Neural Network (GNN) on the KG, which creates an embedding of a new item by combining all of its neighbors that are known to exist. Hao et al. [25] the neighbors’ differences are ignored by their model, which aggregates them using basic pooling techniques.
The APCM model [26] introduces an attention mechanism into relationship paths, assigning different weights to each generated path based on its importance by comparing the semantic similarity between each path and the candidate relationship. The PKICLA model uses CNN and Bi-LSTM to extract semantic features of multiple paths and calculates the probability score for the validity of the candidate triplets.
An extensive overview of the RPEN-KGC model’s architecture and training procedure is given in this section. The model’s relationship path reasoning engine and expert path sampler make up the bulk of its structure, as seen in Figure 1. The reasoning engine is based on a generative adversarial network (GAN) framework. It uses input expert paths as reasoning strategies, trains the generator in the knowledge graph to generate more reliable paths as completion results. The sampler performs local and global sampling on the relationship paths between entity pairs, providing more diverse expert paths for the reasoning engine to use as reasoning evidence.
In the RPEN-KGC model, the reasoning engine consists of a generator and a discriminator. The generator performs random walks in the knowledge graph to generate many relationship paths. These paths are then input, along with the expert paths generated by the sampler, into the discriminator. The discriminator evaluates the semantic similarity between the generated paths and the expert paths as reasoning evidence, providing feedback to the generator for parameter adjustment. Once the discriminator and generator have undergone enough adversarial training, reliable paths that match the expert path distribution can be found, which can then be used for knowledge graph of artificial intelligence of social things completion.
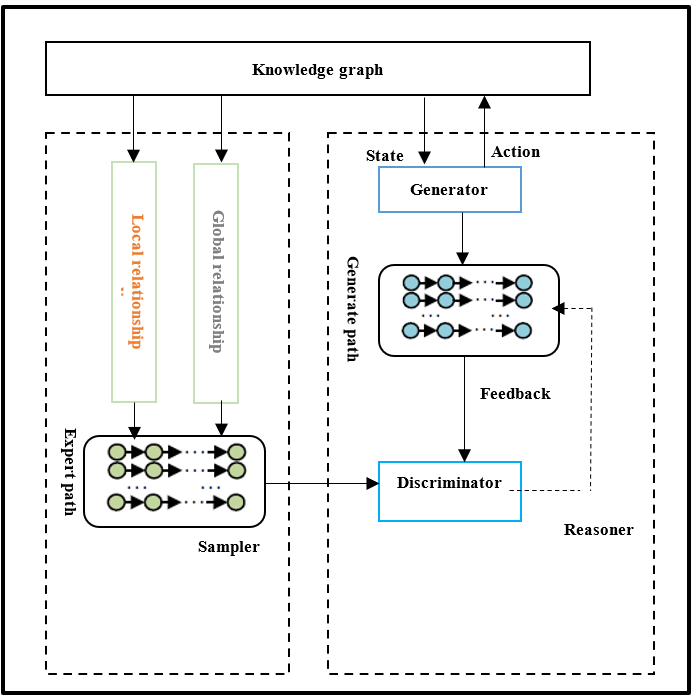
To find reliable paths that match the expert paths in the semantic space, the generator is constructed using a policy-based agent in reinforcement learning. Since convolutional neural networks (CNNs) have high performance in semantic feature extraction, the discriminator is constructed using a CNN, which helps better distinguish between the generated paths and the expert paths semantically. The generated paths and expert paths are packaged for each entity pair in the form of path bundles, and semantic feature extraction is performed. Figure 2 provides a basic schematic diagram of the path bundle embedding representation.
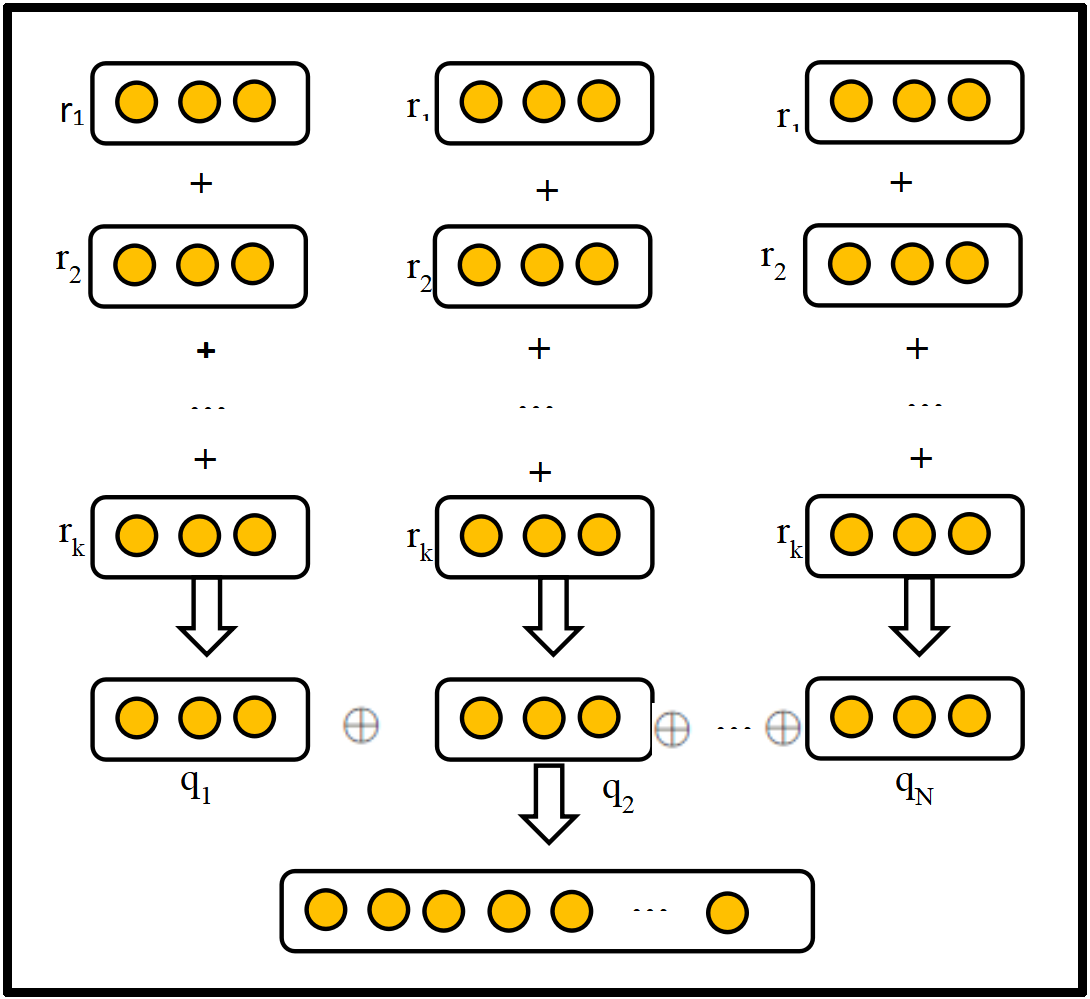
The path is embedded as:
Each path is composed of k relations, and each relation is embedded using the TransE method, mapping it into a vector .
Each path bundle t contains N paths. By embedding and concatenating all paths in the bundle, a real-valued matrix is obtained.
where, represents the concatenation operator for the path bundle .
After encoding the path bundle, it is input into a discriminator based on a convolutional neural network to extract its semantic features. First, local features are extracted through a convolutional layer activated by ReLU non-linear activation.
where, is the convolution kernel, and is the bias coefficient.
Then, semantic features are further extracted through two fully connected layers:
For simplicity, the corresponding bias terms are omitted in the equations. and represent the linear transformation matrices of two different fully connected layers. The output of Equation (4) is normalized using the sigmoid function, while other layers employ the ReLU function for non-linear transformation.
The probability of generating a path as an expert path is calculated using the sigmoid function, and the knowledge graph of artificial intelligence of social things is completed based on the probability results.
Local Relation Sampling: The knowledge graph uses a bidirectional breadth-first search strategy to discover the shortest path between each entity pair. The correlations between entity pairs are more directly reflected in shorter paths. Although longer paths may hold hidden value, they are more likely to introduce noise, which can reduce the quality of expert paths. By performing local relation sampling for each entity pair, an initial expert path set E is obtained.
Global Relation Sampling: Static sampling techniques are easy to use, but they produce fewer expert paths and ignore each entity’s local context in the artificial intelligence of social objects knowledge network. As a result, this research suggests a sampling strategy based on entity neighborhood similarity. For each query triple, the method extracts its relation r and the entity pairs directly connected to it in the knowledge graph as the sampling set. Using the distribution characteristics of word vectors in the semantic space (i.e., the more similar the attribute information or descriptions of entities, the closer they are in the embedding space), the similarity between the entity pairs in the given triple and those in the sampling set is measured via vector dot product. A higher result indicates greater similarity between the entities. To better transfer relation to other entity pairs, entity pairs with high similarity scores for both head and tail entities are selected for subsequent path exploration.
For the relation in a given triple, all entities connected to form the set , and the tail entities among them form the set . In the knowledge graph of artificial intelligence of social things, through random walk, if any entity in the set reaches after several steps, the path is recorded as , and all obtained from the relationship are taken as its characteristic path set . represents the number of characteristic paths in . After the path exploration is completed, the symbol represents the characteristic path obtained by the relationship . In order to ensure the quality of the expert path, the number of random walk steps is set to 3. The possibility of the head entity reaching through each path is:
where, is the sub-part of the path without the tail relation , and represents the probability that reaches through the relation:
where, represents the degree of association between entities obtained through cosine similarity and is used in the result calculation. Cosine similarity is used to determine the degree of link between items, and this information is used to calculate the result. The dynamic sampling model’s parameters are trained in this study using a logistic regression approach, which also maps the computation. Using the sampler and generator, sampling and learning are carried out for every entity pair throughout the training phase. Some baseline models find this difficult, requiring manual hyperparameter modifications to fit various datasets. Creating appropriate hyperparameters by hand might be challenging. This paper employs a logistic regression algorithm to train the parameters of the dynamic sampling model and maps the computation results to the range using the sigmoid function.
where, represents the probability of successfully transferring the relation from a given triple to other entity pairs. A higher value indicates a greater likelihood of successful transfer.
During the training phase, for each entity pair, sampling and learning are performed using the sampler and generator. Based on whether the agent can reach the target entity along the currently collected paths, corresponding expert path sets and generated path sets are created. The collected paths are then grouped into different path bundles: expert path bundles and generated path bundles .
For each path bundle pair , the discriminator aims to clearly distinguish between and . To make the adversarial training process more stable and effective, the RPEN-KGC model updates the discriminator using the loss function proposed in the WGAN-GP model.
where , and represent the critic function, gradient penalty function, and discriminator loss function, respectively. is the gradient penalty coefficient, and is uniformly sampled between and . Based on the feedback from the discriminator, the reward is calculated as:
where, represents noise embeddings composed of continuous uniformly distributed random noise, denotes the characteristic function indicating the validity of the bundle , and represents the set of all valid generated paths. By rewarding valid paths with higher expectations compared to noise embedding , poor-quality paths are filtered out, improving the efficiency of convergence during training.
Finally, the loss function of the discriminator is optimized using the mini-batch stochastic gradient descent algorithm, while the generator is updated using the Adam algorithm [27].
In this study, two commonly used datasets for knowledge graph of artificial intelligence of social things completion experiments: NELL-995 [28] and FB15K-237 [29], for link prediction. Detailed information is shown in Table 1. The link prediction task’s NELL-995 and FB15K-237 datasets demonstrate that RPEN-KGC significantly outperforms baseline methods in the majority of metrics. These results demonstrate that RPEN-KGC is capable to accurately predicting knowledge graphs’ missing data.
NELL-995: This dataset is derived from the NELL system [30] after the 995th iteration. It selects triples corresponding to the top 200 most frequently occurring relations.
FB15K-237: This is a subset of FB15K [31], where many reversible relation triples are removed. This adjustment was made because models relying on reversible relation principles in certain triples can achieve optimal results, making it difficult to distinguish the true performance of different models.
| Datasets | #entities | #relations | #Train Set | #Valid Set | #Test Set | #Tasks |
|---|---|---|---|---|---|---|
| NELL-995 | 75492 | 200 | 154213 | 5000 | 5000 | 12 |
| FB15K-237 | 14541 | 237 | 272115 | 17535 | 20466 | 20 |
| Dataset Model | NELL-995 | FB15K-237 | |||||
|---|---|---|---|---|---|---|---|
| MAP | MRR | Hits@1 | Hits@3 | MAP | MRR | Hits@1 | |
| TransE | 0.737 | 0.715 | 0.608 | 0.702 | 0.532 | 0.286 | 0.190 |
| TransR | 0.789 | 0.727 | 0.631 | 0.714 | 0.54 | 0.315 | 0.216 |
| DistMult | 0.649 | 0.860 | 0.752 | 0.865 | 0.534 | 0.241 | 0.155 |
| Single-Model | 0.827 | 0.833 | 0.765 | 0.903 | 0.525 | 0.512 | 0.496 |
| ConvE | 0.812 | 0.862 | 0.826 | 0.919 | 0.536 | 0.509 | 0.430 |
| DRGI | 0.823 | 0.848 | 0.821 | 0.923 | 0.575 | 0.567 | 0.492 |
| PTransE | 0.793 | 0.838 | 0.723 | 0.793 | 0.547 | 0.381 | 0.361 |
| DeepPath | 0.796 | 0.852 | 0.808 | 0.884 | 0.572 | 0.495 | 0.449 |
| APCM | 0.838 | 0.847 | 0.783 | 0.905 | 0.558 | 0.556 | 0.513 |
| JGAN | 0.853 | 0.851 | 0.779 | 0.874 | 0.561 | 0.564 | 0.517 |
| PKICLA | 0.846 | 0.856 | 0.829 | 0.941 | 0.564 | 0.589 | 0.528 |
| RPEN-KGC | 0.887 | 0.859 | 0.827 | 0.953 | 0.659 | 0.686 | 0.531 |
To evaluate the performance of the model, this study adopts commonly used metrics in the task of knowledge graph completion: MAP (mean average precision), MRR (mean reciprocal rank), and Hits@k.
Hits@k: Indicates the probability that the correct triple is ranked among the top kkk. A higher value suggests better performance of the knowledge graph completion method.
MRR (Mean Reciprocal Rank): Represents the average reciprocal rank of the correct triples. A higher value indicates better model performance.
MAP (Mean Average Precision): Refers to the mean of the prediction rankings for head or tail entities. A higher value reflects better model performance. The definitions are as follows:
In this case, the ranks of positive samples are represented by while those of negative samples are represented by . Here, stands for the test set and for the overall sample size.
The model is tested against multiple baseline models to ensure its efficacy:
In the experiments, every path bundle has N=5 paths, and the embedding dimension is set at 200. In this convolutional neural network, the parameters 3×N for the convolution kernel, for the gradient penalty, 1024 for the hidden layer, and a size for the output layer that corresponds to the path embedding dimension are all set. L2 regularization is used to avoid overfitting.
During testing, invalid triples are scored alongside valid triples at a ratio of approximately 1:10, with invalid triples generated by randomly replacing entities.
Table 2 displays the link prediction experiment outcomes in comparison to baseline models. Compared to NELL-995, RPEN-KGC performs better than the majority of baseline models, especially on larger datasets like FB15K-237, which has a more complex distribution of relation types. Specifically:
NELL-995: The proposed model outperforms translation-based models significantly. While semantic matching-based models and relation path-based models score higher on NELL-995, their performance drops on FB15K-237, likely due to the interference from reversible relations. On NELL-995, RPEN-KGC is slightly behind some models in MRR and Hits@1 metrics. However, it improves over the best-performing models by 0.034 and 0.012 in MAP and Hits@3, respectively.
FB15K-237: RPEN-KGC achieves the best results across all metrics. Compared to the best-performing fusion-based models, it improves MAP, MRR, Hits@1, and Hits@3 by at least 0.084, 0.097, 0.003, and 0.009, respectively.
Comparison Insights:
On NELL-995, compared to ConvE and DistMult, RPEN-KGC shows a slight drop in MRR (by 0.003 and 0.001, respectively). This is because NELL-995 contains fewer paths for certain entity pairs, whereas RPEN-KGC requires a large number of paths for expert and generated paths. DistMult uses a bilinear scoring function for triples, and ConvE employs 2D convolution to process entity and relation embeddings, effectively extracting entity similarity features and enhancing performance.
Compared to PKICLA, RPEN-KGC’s Hits@1 is slightly lower because PKICLA not only extracts local features of relation paths but also uses an attention mechanism to assign weights to multiple paths, extracting global features and thus achieving prominent performance.
An entity neighbourhood similarity comparison mechanism is also included in the model, which offers the reasoner a large number of trustworthy expert pathways and successfully facilitates semantic interaction between relation paths and entity neighbourhood data. Experiments on two publicly accessible knowledge graph completion datasets show that the RPEN-KGC model performs better than baseline methods on the majority of metrics.
On FB15K-237, RPEN-KGC consistently achieves the best performance across all evaluation metrics. This is due to two key reasons:
Compared to other models, RPEN-KGC fully extracts relational path features through adversarial training between expert and generated paths, while also leveraging entity similarity to improve the success rate of expert path mining and capturing entity feature information.
FB15K-237’s complex relation types make it challenging for some baseline models, which require manual hyper parameter adjustments to fit different datasets. Designing suitable hyper parameters manually can be complex. However, RPEN-KGC automatically optimizes parameters through generative adversarial networks and uses a sampler to unsupervised extract many reliable expert paths from the knowledge graph of artificial intelligence of social things.
As a result, RPEN-KGC demonstrates more stable performance and better real-world applicability compared to other models.
Relationship paths and entity neighbourhood data are combined for knowledge graph fused using a novel method called RPEN-KGC (Relationship Path and Entity Neighbourhood Knowledge Graph Completion). The sampler provides the inferencer with reliable inference methods by randomly walking between entity pairs. To increase sampling efficiency and support inference methodologies, the sampler steers random walks using a contrastive method based on entity neighborhood similarity. The inferencer infers a wider range of relationship paths within the semantic domain and extracts semantic properties of relationship paths. RPEN-KGC greatly improves most metrics compared to baseline methods, according to experiments conducted on the publicly available NELL-995 and FB15K-237 datasets for the link prediction task. These results show that RPEN-KGC effectively predicts knowledge graphs with missing information.
To validate the effectiveness of the model’s components, an ablation study was conducted by removing certain components of the model and retraining on the FB15K-237 and NELL-995 datasets. This quantifies the contributions of each component. The three model variants in this study are as follows:
Removal of the Global Relation Sampling Module: The model uses only the local relation sampling method to obtain expert paths during training.
Removal of the Local Relation Sampling Module: The model uses only the global relation sampling method to obtain expert paths during training.
Removal of the Sampler Module: The model conducts experiments using only the reinforcement learning approach.
On the NELL-995 and FB15K-237 datasets, the MAP metric is used to evaluate the link prediction performance of the model. The experimental results are shown in Table 3.
| Model | MAP | |
|---|---|---|
| NELL-995 | FB15K-237 | |
| Model in this paper | 0.887 | 0.659 |
| w/o local relation sampling | 0.817 | 0.651 |
| w/o global relation sampling | 0.802 | 0.643 |
| w/o sampler | 0.796 | 0.572 |
After removing the local relation sampling module, global relation sampling module, and sampler module, the MAP metric of the model shows varying degrees of decline.
After removing the local relation sampling module, the model only uses global relation sampling to obtain multi-hop paths between entities as expert paths, ignoring the most direct path relationships between entities. The MAP score is close to but lower than that of the original model.
After removing the global relation sampling module, the model cannot dynamically adjust hyper parameters and lacks attention to entity environmental features. It only uses a small number of single-hop paths between entities as expert paths, resulting in a MAP score significantly lower than the original model.
After removing the sampler module, the model degenerates to DeepPath, and it performs the worst compared to the other ablation models.
The ablation study results demonstrate the rationality of each component in RPEN-KGC.
In order to develop reasoning paths for the completion task and hence increase the model’s robustness to noisy data, the RPEN-KGC model employs a generator-adversarial network-based reasoning engine to train adversarial on the generated samples and expert samples created by random walks.
This paper proposes a knowledge graph completion method, RPEN-KGC, that integrates relation paths and entity domain information. By using a generative adversarial network, it captures many relation paths from the knowledge graph of intelligence of social things. Additionally, by extracting semantic features from these relation paths, it generates more diverse reasoning paths in the semantic space. The model also incorporates an entity neighbourhood similarity comparison mechanism, providing many reliable expert paths for the reasoner and effectively enabling semantic interaction between relation paths and entity neighbourhood information.
Experiments on two publicly available datasets for knowledge graph completion demonstrate that the RPEN-KGC model outperforms baseline models on most metrics. In future research, this method will be enhanced by incorporating multimodal information to further improve the effectiveness of knowledge graph completion.
 Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/