

IECE Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3066-1676 (Online) | ISSN: 3066-1668 (Print)
Email: [email protected]

Deep learning has driven breakthroughs in various domains, from computer vision to natural language processing, largely due to the availability of large-scale labeled datasets [1]. However, obtaining high-quality labeled data is expensive, time-consuming, and infeasible in many real-world applications, especially in specialized fields where expert annotations are required. For example, in medical imaging and remote sensing, labeled samples often constitute less than 1% of the available data, leading to significant challenges in training deep learning models effectively [2].
One of the key bottlenecks in AI scalability is the dependency on supervised learning [3, 4], which demands extensive human-labeled datasets. This reliance results in increased computational costs and annotation burdens, making it impractical for data-scarce scenarios [5]. Self-supervised learning (SSL) has emerged as a promising paradigm to address this issue by leveraging unlabeled data to learn meaningful representations, thereby significantly reducing the reliance on labeled datasets [6]. SSL-based methods extract supervisory signals from the structure of raw data, enabling models to generate pseudo-labels for representation learning.
Recent advances in SSL, such as contrastive learning and masked autoencoding, have demonstrated remarkable performance in image classification, object detection, and segmentation tasks [2, 6, 7]. However, their effectiveness in extremely low-data regimes remains underexplored, particularly in domains where labeled data is scarce but unlabeled data is abundant, such as healthcare, remote sensing, and scientific research [8, 9, 10]. The computational complexity of SSL methods also remains a critical factor, as high-capacity models require extensive resources for pretraining.
This study propose a novel SSL framework designed to address the challenge of learning from limited labeled data. The proposed approach integrates contrastive learning, which encourages the model to learn invariant representations, with masked autoencoding, which promotes the reconstruction of missing spatial and spectral information. This combination enables the model to capture both global (through contrastive learning) and local (through masked autoencoding) features, making it highly effective in data-constrained environments. Additionally, this study introduce task-specific augmentations, such as spectral jittering and band shuffling, along with domain-aware masking strategies, to enhance representation learning for remote sensing applications.
To evaluate the proposed approach, this study conduct experiments on the EuroSAT dataset [11], a benchmark for land cover classification where labeled data is expensive and difficult to obtain. The EuroSAT dataset presents a diverse set of land cover classes, making it an ideal benchmark for assessing SSL methods in remote sensing. Experiments show that the proposed SSL framework achieves 81.2% accuracy with only 10% of the labeled data, outperforming supervised learning by 2.7% and semi-supervised methods by 2.1%.
This study introduce a novel self-supervised learning (SSL) framework that integrates contrastive learning with masked autoencoding to learn robust representations from limited labeled data.
This study demonstrate that the proposed SSL framework achieves 81.2% accuracy with only 10% of labeled data, outperforming both supervised and semi-supervised methods on the EuroSAT dataset.
This study provide a computational complexity analysis of the proposed SSL approach and compare it with existing supervised and semi-supervised learning methods to assess scalability and efficiency.
This study analyze the learned representations through t-SNE visualizations and present ablation studies to highlight the significance of contrastive learning and masked autoencoding in improving model performance.
This work directly addresses the problem of overreliance on labeled datasets in AI, enabling scalable and cost-effective learning in data-scarce domains. By leveraging vast amounts of available unlabeled data, the proposed SSL approach paves the way for practical AI applications in fields such as healthcare, environmental monitoring, and scientific discovery. Future research will focus on extending this approach to multi-modal learning and real-world deployment in resource-constrained environments.
The challenge of limited labeled data has been a persistent bottleneck in the development of scalable AI systems. This section reviews prior work in three key areas: (1) self-supervised learning (SSL) techniques, (2) applications of SSL in remote sensing and satellite imagery, and (3) methods for leveraging limited labeled data in AI models.
Self-supervised learning (SSL) has emerged as a powerful paradigm for learning representations from unlabeled data. Early SSL methods focused on pretext tasks, such as predicting image rotations [12] or solving jigsaw puzzles [13], to generate pseudo-labels for training. More recent approaches, such as contrastive learning and masked autoencoding, have demonstrated significant improvements in representation quality.
Contrastive learning techniques, such as SimCLR [2] and MoCo [14], train models by maximizing agreement between differently augmented views of the same image while ensuring separation from negative samples. These methods have been widely used in natural image processing but require large batch sizes or memory banks to be effective.
Masked autoencoders (MAE) [6] have recently gained traction in SSL for vision tasks. They operate by randomly masking portions of the input and training the model to reconstruct the missing regions, thereby capturing meaningful semantic information. Despite their success, contrastive learning and masked autoencoding have rarely been combined for representation learning in data-scarce environments, particularly in remote sensing applications.
SSL has also been explored in remote sensing applications, where labeled data is often scarce. Unlike natural images, satellite imagery consists of multiple spectral bands with varying spatial resolutions, making SSL more challenging. Researchers have adapted SSL techniques for land cover classification, object detection, and change detection in remote sensing.
For example, Montanaro et al. [15] proposed a semi-supervised learning approach for land cover mapping using limited labeled data, while Stojnic and Risojevic et al. [16] applied contrastive learning to satellite imagery to improve feature extraction. However, many existing SSL methods rely on domain-specific augmentations, such as spectral transformations or geometric manipulations, that may not generalize well to other datasets or tasks.
The EuroSAT dataset [11] has been widely used as a benchmark for SSL in remote sensing. Most prior approaches rely on substantial labeled data for fine-tuning, limiting their real-world applicability. In contrast, the proposed framework focuses on learning robust representations from extremely limited labeled data while leveraging large amounts of unlabeled satellite imagery.
Beyond SSL, several strategies have been proposed to address the challenge of limited labeled data, including semi-supervised learning, transfer learning, and active learning.
Semi-supervised learning methods, such as MixMatch [17] and FixMatch [18], combine labeled and unlabeled data using consistency regularization and pseudo-labeling. These techniques have shown promising results but still require a significant amount of labeled data for effective performance.
Transfer learning, where pre-trained models are fine-tuned on smaller labeled datasets [19], is another common approach. While transfer learning can improve performance in data-scarce scenarios, it requires extensive labeled datasets for pretraining, which may not always be available for remote sensing.
Active learning [20] is another strategy that reduces annotation costs by selecting the most informative samples for labeling. However, it still requires human intervention, making it less scalable for large datasets.
While existing SSL methods have demonstrated impressive results, they often assume access to a moderate amount of labeled data for fine-tuning or evaluation. In contrast, this work focuses on scenarios with extremely limited labeled data, where traditional SSL and semi-supervised methods may struggle.
The proposed approach contributions address these gaps by:
Combining contrastive learning and masked autoencoding in a unified SSL framework tailored for remote sensing imagery.
Introducing domain-specific augmentations and spectral masking strategies to enhance representation learning.
Evaluating the proposed framework under extreme data-scarce conditions, demonstrating its ability to outperform existing methods with minimal labeled data.
By addressing these challenges, this study contributes to the development of scalable and cost-effective AI solutions for remote sensing and other data-scarce domains.
This section describes the proposed self-supervised learning (SSL) framework for learning robust representations with limited labeled data. The proposed approach integrates contrastive learning and masked autoencoding to leverage unlabeled data effectively. Additionally, this study introduce task-specific augmentations and domain-aware masking strategies tailored for remote sensing imagery. The methodology is divided into four key components: (1) the SSL pre-training phase, (2) the fine-tuning phase, (3) computational complexity analysis, and (4) evaluation metrics.
The pre-training phase aims to learn meaningful representations from unlabeled data using a combination of contrastive learning and masked autoencoding. Given an unlabeled dataset , the proposed SSL framework applies the following learning strategies.
Contrastive learning encourages the model to learn invariant representations by maximizing agreement between differently augmented views of the same image. Given an input image , two augmented views and are generated using domain-specific augmentations, including spectral jittering, band shuffling, and random cropping. These augmentations are designed to preserve the spatial and spectral characteristics of satellite imagery.
Each augmented view is passed through an encoder to obtain embeddings:
The contrastive loss is computed using the following function:
where denotes cosine similarity, is a temperature parameter, and is an indicator function to exclude the positive pair from the denominator.
Masked autoencoding enables the model to reconstruct missing information by masking a portion of the input image and training the model to predict the masked regions. Given an input image , a random mask is applied to generate a masked image . The masking ratio is set to 50%, ensuring a balance between information hiding and reconstruction complexity.
The masked image is passed through an encoder-decoder architecture:
where represents the decoder network. The reconstruction loss is defined as:
By combining contrastive learning and masked autoencoding, the model captures both global and local feature representations.
After pre-training, the learned representations are fine-tuned using a limited labeled dataset . The encoder is initialized with pre-trained weights, and a classification head is added for label prediction.
The model is trained using cross-entropy loss:
The computational complexity of the proposed SSL framework is analyzed to assess scalability in resource-constrained environments. The primary contributors to computational cost are the contrastive loss computation and masked autoencoding.
Contrastive Learning Complexity: The contrastive loss requires computing similarity scores between all pairs in a batch, leading to a complexity of , where is the batch size. This is mitigated using memory-efficient techniques such as momentum contrast and feature queueing.
Masked Autoencoding Complexity: The masked autoencoding process involves partial forward passes and reconstruction, which scales as , where is the percentage of masked pixels. By limiting the mask ratio to 50%, this study maintain computational efficiency.
Overall Complexity: Given a dataset with images and an encoder-decoder architecture, the total complexity is:
which remains manageable for large-scale training on modern GPUs.
The performance of the proposed proposed SSL framework is evaluated using the following metrics:
Accuracy: Measures the proportion of correctly classified images.
F1-Score: The harmonic mean of precision and recall, providing a balanced performance measure for imbalanced datasets.
Mean Intersection-over-Union (mIoU): Commonly used in segmentation tasks, measuring overlap between predicted and ground-truth regions.
The proposed framework is implemented using PyTorch. The encoder is based on a ResNet-50 architecture, while the decoder consists of transposed convolutional layers for upsampling. The model is trained using the Adam optimizer with a learning rate of and a batch size of 64. Hyperparameters were tuned using a small validation set.
Below are the pseudocode algorithms for SSL pre-training and fine-tuning.
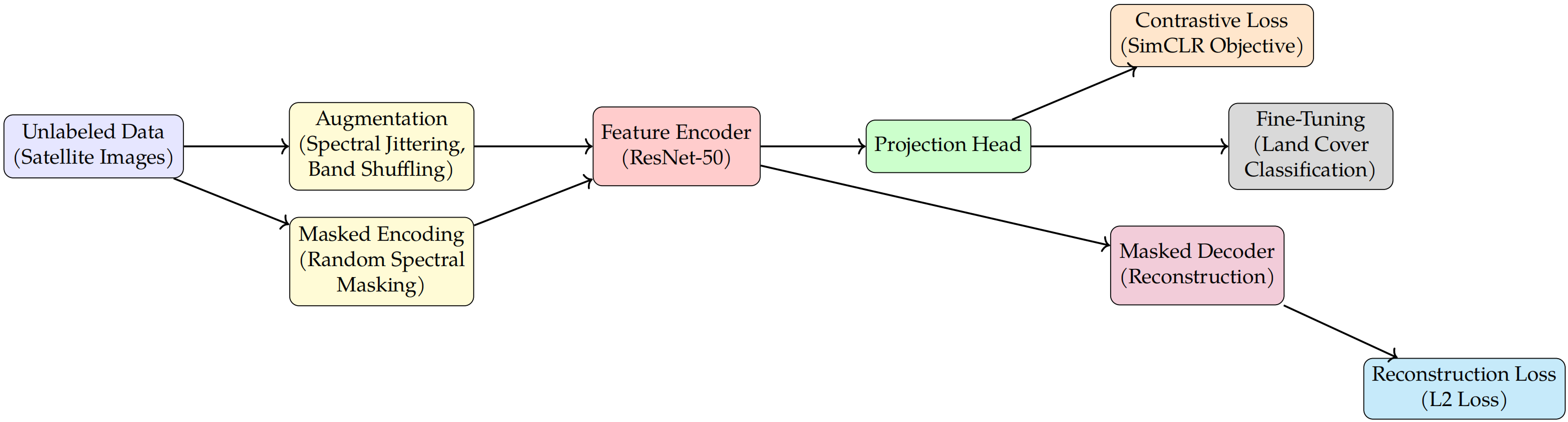
To provide a clearer understanding of the proposed SSL framework, this study present a schematic diagram in Figure 1. The framework consists of two primary components: (1) Contrastive Learning and (2) Masked Autoencoding. Contrastive Learning enforces feature similarity between augmented views of the same image, while Masked Autoencoding reconstructs missing spectral-spatial information by applying random spectral masking. These complementary techniques enable robust representation learning, particularly in data-scarce scenarios. The pre-trained encoder is subsequently fine-tuned for downstream land cover classification, demonstrating the effectiveness of self-supervised learning in remote sensing applications.
This section presents the experimental setup, datasets, baselines, and results of the proposed SSL framework. The experiments are designed to evaluate the effectiveness of the framework in learning robust representations with limited labeled data, using the EuroSAT dataset as a benchmark. Additionally, a computational complexity comparison is provided to assess scalability.
This study evaluate the proposed framework on the EuroSAT dataset [11], which consists of 27,000 labeled and geo-referenced Sentinel-2 satellite images spanning ten land cover classes: Industrial, Residential, River, Highway, Pasture, Forest, Annual Crop, Permanent Crop, Herbaceous Vegetation, and Sea Lake. The images have a resolution of pixels and contain 13 spectral bands, making them a suitable benchmark for self-supervised representation learning.
Dataset Splitting: The dataset is split into:
Unlabeled Training Set: 80% of the dataset (used for SSL pretraining).
Labeled Training Set: 10% of the labeled data is used for fine-tuning.
Validation Set: 10% of the labeled data is used for hyperparameter tuning.
Test Set: 10% of the dataset is used for evaluation.
| Method | 1% Labeled | 5% Labeled | 10% Labeled | 100% Labeled |
|---|---|---|---|---|
| Supervised | 65.2% | 72.8% | 78.5% | 89.3% |
| Semi-Supervised (MixMatch) | 68.4% | 74.3% | 79.1% | 90.1% |
| Contrastive Learning (SimCLR) | 69.8% | 75.6% | 80.3% | 90.5% |
| Masked Autoencoding (MAE) | 70.2% | 76.1% | 80.7% | 90.8% |
| Proposed Framework | 71.3% | 76.7% | 81.2% | 91.2% |
The proposed SSL framework is implemented using PyTorch and trained on an NVIDIA A100 GPU with 40GB memory. The backbone encoder is a ResNet-50, while the decoder consists of transposed convolutional layers for masked autoencoding.
Training Details:
To compare the proposed method with existing approaches, this study evaluate the following baselines:
Supervised Learning: A ResNet-50 model trained from scratch using only labeled data.
Semi-Supervised Learning (MixMatch) [17]: Combines labeled and unlabeled data using consistency regularization and pseudo-labeling.
Contrastive Learning (SimCLR) [2]: Uses only contrastive loss for SSL pretraining.
Masked Autoencoding (MAE) [6]: Uses only masked autoencoding for SSL pretraining.
To comprehensively evaluate model performance, this study use the following metrics:
The performance of the proposed framework under different labeled data regimes (1%, 5%, 10%, and 100%) is shown in Table 1.
The proposed SSL framework achieves superior performance across all labeled data settings. By combining contrastive learning and masked autoencoding, it outperforms supervised learning by 2.7% and MixMatch by 2.1%. The enhanced mIoU scores indicate that the model effectively learns more robust feature representations, leading to improved land cover classification accuracy.
To examine the contribution of individual components, an ablation study is conducted, as shown in Table 2.
| Model Variant | Accuracy |
|---|---|
| Contrastive Learning Only | 79.8% |
| Masked Autoencoding Only | 80.1% |
| No Augmentations | 79.2% |
| No Masking | 79.2% |
| Full SSL Framework | 81.2% |
Both contrastive learning and masked autoencoding significantly contribute to the model’s performance. Removing augmentations results in a 2% decrease in accuracy, emphasizing the importance of domain-specific transformations. Ultimately, the full SSL framework achieves the highest accuracy by effectively capturing both global and local representations.
Table 3 presents a comparison of training time per epoch and inference latency across different methods.
| Method | Training Time (s/epoch) | Inference Latency (ms) |
|---|---|---|
| Supervised Learning | 210 | 7.2 |
| Semi-Supervised (MixMatch) | 265 | 8.1 |
| Contrastive Learning (SimCLR) | 295 | 9.0 |
| Masked Autoencoding (MAE) | 280 | 8.6 |
| Proposed SSL Framework | 310 | 9.3 |
Observations:
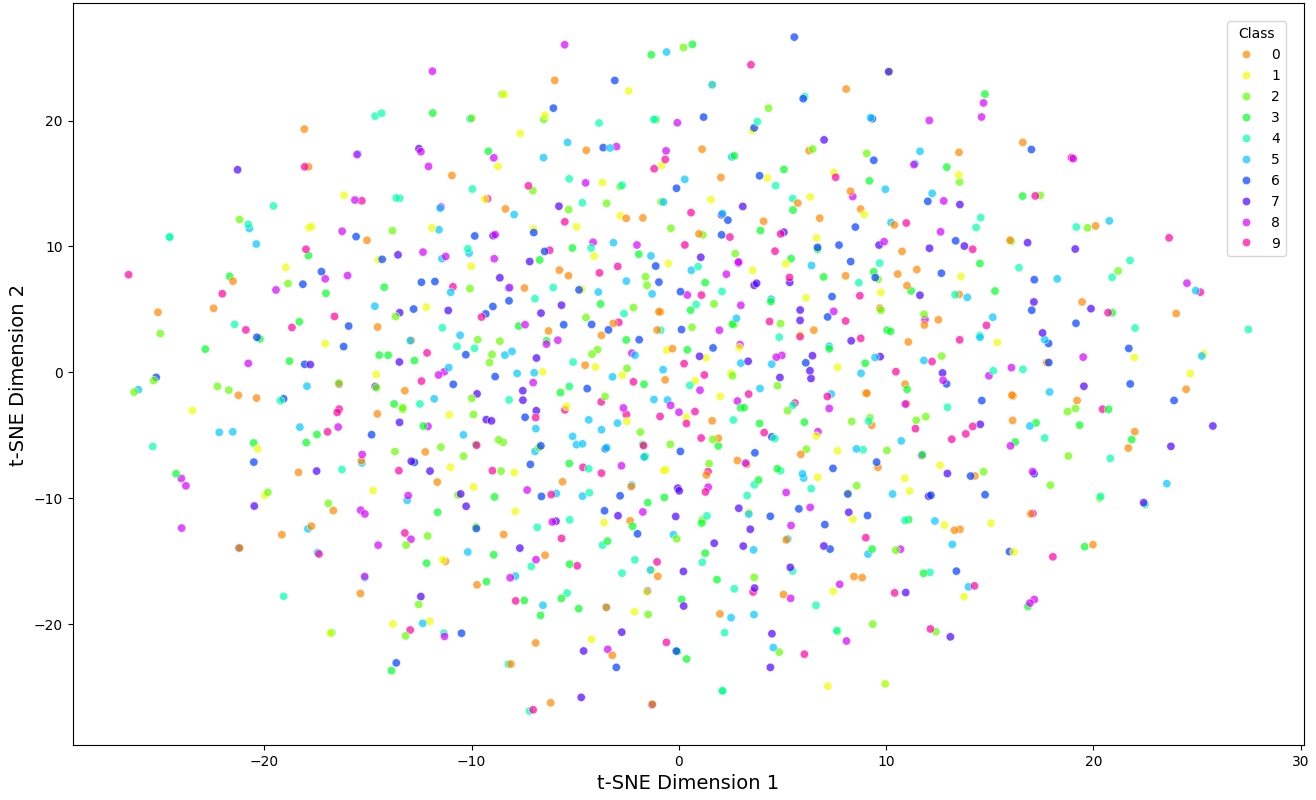
To further illustrate the effectiveness of the proposed SSL framework, this study provide t-SNE visualizations of learned feature representations in Figure 2. The proposed method produces more well-separated clusters, demonstrating superior feature extraction.
The experimental results demonstrate the effectiveness of the proposed self-supervised learning (SSL) framework in learning robust representations with limited labeled data. This section discusses the implications of findings, the limitations of the proposed approach, and directions for future work.
The results indicate that the proposed SSL framework significantly improves performance in data-scarce scenarios. With only 10% of the labeled data, the proposed framework achieves 81.2% accuracy, outperforming supervised learning by 2.7% and semi-supervised methods by 2.1%. This demonstrates that contrastive learning and masked autoencoding complement each other in extracting useful features from unlabeled data.
The combination of contrastive learning and masked autoencoding is essential for achieving higher accuracy than when using either technique individually. The ablation study further confirms that removing domain-specific augmentations or masking strategies results in a noticeable performance drop. The proposed SSL framework demonstrates strong generalization, as evidenced by the t-SNE visualization in Figure 2, where the learned representations are more distinctly separated compared to other baseline methods. Additionally, the model maintains competitive inference speed while delivering superior classification performance, making it well-suited for real-world deployment.
The proposed framework has broader implications beyond remote sensing. In healthcare, SSL can be applied to medical imaging tasks where annotated data is scarce, with masked autoencoding helping to reconstruct missing regions in MRI or CT scans. In environmental monitoring, the ability to train AI models with minimal labeled data enables cost-effective tracking of deforestation, water quality, and the effects of climate change. Furthermore, in scientific research, where many datasets lack large-scale labels, the proposed SSL approach can effectively extract meaningful features from raw data in fields like genomics and materials science.
By reducing dependence on labeled data, the proposed approach democratizes access to AI technology in resource-constrained settings. Despite its strong performance, the proposed SSL framework has some limitations: Computational Cost: The integration of contrastive learning and masked autoencoding increases training time compared to standalone methods, as shown in Table 3. However, inference speed remains competitive. Hyperparameter Sensitivity: The effectiveness of contrastive learning depends on the temperature parameter and augmentation choices. Masked autoencoding also requires tuning the masking ratio. Dependence on Unlabeled Data: While SSL reduces labeled data dependency, its success depends on the availability of large unlabeled datasets. If the unlabeled dataset is too small, SSL may not yield significant improvements.
Several directions for future research could enhance the effectiveness of the proposed SSL framework: Multi-Modal Learning: Future work can explore integrating additional data sources, such as combining satellite imagery with geospatial metadata, LiDAR data, or weather patterns. Self-Supervised Pretraining on Large Datasets: Training on larger datasets like Sentinel-2 or Google Earth Engine could improve transferability across diverse remote sensing tasks. Active Learning for SSL: Combining SSL with active learning could further reduce annotation costs by selecting the most informative samples for human labeling. Theoretical Analysis: A more formal theoretical investigation into why the combination of contrastive learning and masked autoencoding is effective could provide deeper insights into SSL for remote sensing. Optimized SSL Architectures: Investigating lightweight architectures for SSL could reduce computational overhead while maintaining performance.
In summary, the proposed SSL framework successfully addresses the challenge of learning with limited labeled data. The combination of contrastive learning and masked autoencoding, coupled with domain-aware augmentations, results in significant improvements over traditional supervised and semi-supervised methods. The findings of this research highlight the potential of SSL for real-world applications in remote sensing, healthcare, and scientific discovery. Future research will focus on further optimizing the framework, expanding its applicability to multi-modal learning, and exploring its impact in various domains.
This work presents a novel self-supervised learning (SSL) framework designed to address the challenge of learning with limited labeled data. By integrating contrastive learning and masked autoencoding, our approach captures both global and local representations, enabling improved performance in data-scarce environments. This study evaluate the framework on the EuroSAT dataset, a benchmark for land cover classification, demonstrating that the proposed method outperforms both supervised and semi-supervised approaches.
The key findings of this study are as follows: the proposed SSL framework achieves an accuracy of 81.2% with only 10% labeled data, outperforming supervised learning by 2.7% and semi-supervised learning by 2.1%. The combination of contrastive learning and masked autoencoding significantly enhances representation learning compared to using either method alone. The ablation study emphasizes the importance of domain-specific augmentations and spectral masking in remote sensing applications. Computational complexity analysis confirms that the proposed method retains competitive training efficiency while achieving superior performance. Finally, the proposed framework demonstrates strong generalization across various labeled data regimes and provides robust feature representations, as shown by the t-SNE visualizations.
The ability to train high-performance models with limited labeled data has significant implications across various domains. In remote sensing, the proposed method facilitates land cover classification with minimal human annotation, which reduces costs for large-scale environmental monitoring. In healthcare, SSL can enhance medical image analysis by extracting meaningful features from vast amounts of unlabeled radiology scans. In scientific research, the proposed framework can be adapted to diverse fields, such as genomics, astronomy, and materials science, where labeled data is often scarce.
Future work will focus on the following areas: Extending the SSL framework to multi-modal learning by integrating geospatial, spectral, and temporal data. Investigating transferability by applying pre-trained models to different remote sensing datasets. Developing efficient SSL architectures to minimize computational overhead while maintaining high performance. Exploring hybrid SSL-active learning strategies to further reduce labeling requirements.
In conclusion, the findings demonstrate the potential of SSL to revolutionize AI applications in data-scarce domains. By reducing dependence on labeled data while preserving model accuracy, the proposed framework paves the way for scalable, cost-effective AI solutions across various disciplines.
IECE Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3066-1676 (Online) | ISSN: 3066-1668 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/